




1. Construire l'environnement de dĂ©veloppement▲
Avant de plonger dans la création d'un système d'exploitation, la première chose est de paramétrer notre environnement de développement. Pour de nombreux tutoriels, cela peut être difficile, vous aurez souvent des erreurs mystérieuses que le tutoriel ne mentionne pas, vous êtes coincé avant même de commencer. Je vais essayer ici de décrire les étapes qui m'ont permis d'avoir un environnement de développement configuré. Je postule par contre que vous travaillez sous environnement Linux.
Ce tutoriel suppose que vous avez une connaissance fonctionnelle de la programmation en langage C, ainsi qu'une compréhension de base des différentes parties d'un ordinateur (CPU, GPU, RAM, etc.). Il ne suppose pas une connaissance antérieure des concepts et designs d'un système d'exploitation. Tout cela vous sera expliqué au fur et à mesure.
1-1. Le compilateur▲
Votre ordinateur fonctionne probablement sur un processeur Intel ou AMD qui utilise l'architecture x86_64 (appelé aussi AMD64). Le processeur Raspberry Pi, quant à lui, utilise l'architecture ARM. Cette différence signifie que vous ne pouvez pas utiliser le compilateur GCC standard qui est probablement déjà installé sur vote machine. Le compilateur que nous voulons est appelé gcc-arm-none-eabi, il peut être téléchargé depuis le site web ARM developer.
Si vous êtes sous Linux, créez un nouveau dossier pour ce projet, et copiez-y les fichiers téléchargés, puis extrayez-les via la commande :
tar -xf gcc-arm-none-eabi-X-XXXX-XX-update-linux.tar.bz2Les X-XXXX peuvent varier selon le moment où vous téléchargez le fichier. Le compilateur devrait être situé dans gcc-arm-none-eabi-X-XXXX-XX-update/bin/arm-none-eabi-gcc.
1-2. La machine virtuelle▲
Cette partie n'est pas strictement nécessaire, mais elle nous rendra les choses plus faciles pour le débogage et les tests. Nous allons utiliser QEMU pour lancer la machine virtuelle. Les nouvelles versions de QEMU peuvent émuler le matériel du Raspberry, mais il est peu probable que la version de votre gestionnaire de paquets la contienne. Il nous faut une version qui ne soit pas inférieure à la version 2.11.0. Nous pouvons construire la dernière version de QEMU depuis le code source en effectuant les opérations suivantes :
wget https://download.qemu.org/qemu-2.11.0.tar.xz
tar xvJf qemu-2.11.0.tar.xz
cd qemu-2.11.0
./configure --target-list=arm-softmmu,arm-linux-user
make -j 2
sudo make installNous pouvons vérifier que cela a fonctionné en lançant la commande qemu-system-arm -- version. Nous avons maintenant un environnement configuré, et pouvons construire un noyau.
2. Avoir quelque chose Ă booter▲
Comme avec tout nouveau projet, la meilleure façon de démarrer est de copier un bout de code depuis quelque part et d'avoir quelque chose qui fonctionne, puis de revenir en arrière et essayer de comprendre le code. J'ai pris ce premier lot de code depuis le wiki OSDev, mais je vais le poster ici et expliquer chaque morceau.
Si vous voulez télécharger le code et jouer vous-même avec, regardez mon dépôt git.
2-1. boot.S - le point d'entrĂ©e du noyau▲
boot.S est la première chose que le matériel exécute dans notre noyau. Il doit être réalisé en assembleur. Quand le matériel charge le noyau, il ne met pas en place un runtime C. Il ne sait pas non plus à quoi cela ressemble. Ce code assembleur installe cela de façon à pouvoir passer rapidement au C. Voici le code :
boot.S
.section ".text.boot"
.global _start
_start:
mrc p15, #0, r1, c0, c0, #5
and r1, r1, #3
cmp r1, #0
bne halt
mov sp, #0x8000
ldr r4, =__bss_start
ldr r9, =__bss_end
mov r5, #0
mov r6, #0
mov r7, #0
mov r8, #0
b 2f
1:
stmia r4!, {r5-r8}
2:
cmp r4, r9
blo 1b
ldr r3, =kernel_main
blx r3
halt:
wfe
b haltPour une explication ligne par ligne de ce code, consultez cette pageUne explication détaillée de boot.S.
2-2. kernel.c - Le code C▲
Ce fichier contient la substance de notre bébé noyau.
L'essentiel du code est la mise en place du matériel pour les opérations basiques d'entrées/sorties. Les entrées/sorties sont effectuées à travers le matériel UART (Universal Asynchronous Receiver Transmitter), lequel nous permet d'envoyer et recevoir des données texte à travers les ports série. La seule façon de profiter de ceci sur le vrai matériel est d'avoir un câble série TTL vers USB. Comme je n'ai pas ce type de câble, je vais interagir avec le noyau à travers la VM jusqu'à ce que nous puissions avoir des accès entrées/sorties plus sophistiqués comme le HDMI et un clavier USB.
À part la configuration du matériel, il y a quelques fonctions d'assistance pour abstraire celui-ci, et bien sûr, la fonction main.
Voici le code :
kernel.c
#include <stddef.h>
#include <stdint.h>
static inline void mmio_write(uint32_t reg, uint32_t data)
{
*(volatile uint32_t*)reg = data;
}
static inline uint32_t mmio_read(uint32_t reg)
{
return *(volatile uint32_t*)reg;
}
// boucle « delay » fois d'une manière non optimisée par le compilateur
static inline void delay(int32_t count)
{
asm volatile("__delay_%=: subs %[count], %[count], #1; bne __delay_%=\n"
: "=r"(count): [count]"0"(count) : "cc");
}
enum
{
// les adresses de base des registres du GPIO.
GPIO_BASE = 0x3F200000, // pour raspi2 et 3, 0x20200000 pour raspi1
GPPUD = (GPIO_BASE + 0x94),
GPPUDCLK0 = (GPIO_BASE + 0x98),
// Les adresses de base pour l'UART.
UART0_BASE = 0x3F201000, // pour raspi2 et 3, 0x20201000 pour raspi1
UART0_DR = (UART0_BASE + 0x00),
UART0_RSRECR = (UART0_BASE + 0x04),
UART0_FR = (UART0_BASE + 0x18),
UART0_ILPR = (UART0_BASE + 0x20),
UART0_IBRD = (UART0_BASE + 0x24),
UART0_FBRD = (UART0_BASE + 0x28),
UART0_LCRH = (UART0_BASE + 0x2C),
UART0_CR = (UART0_BASE + 0x30),
UART0_IFLS = (UART0_BASE + 0x34),
UART0_IMSC = (UART0_BASE + 0x38),
UART0_RIS = (UART0_BASE + 0x3C),
UART0_MIS = (UART0_BASE + 0x40),
UART0_ICR = (UART0_BASE + 0x44),
UART0_DMACR = (UART0_BASE + 0x48),
UART0_ITCR = (UART0_BASE + 0x80),
UART0_ITIP = (UART0_BASE + 0x84),
UART0_ITOP = (UART0_BASE + 0x88),
UART0_TDR = (UART0_BASE + 0x8C),
};
void uart_init()
{
mmio_write(UART0_CR, 0x00000000);
mmio_write(GPPUD, 0x00000000);
delay(150);
mmio_write(GPPUDCLK0, (1 << 14) | (1 << 15));
delay(150);
mmio_write(GPPUDCLK0, 0x00000000);
mmio_write(UART0_ICR, 0x7FF);
mmio_write(UART0_IBRD, 1);
mmio_write(UART0_FBRD, 40);
mmio_write(UART0_LCRH, (1 << 4) | (1 << 5) | (1 << 6));
mmio_write(UART0_IMSC, (1 << 1) | (1 << 4) | (1 << 5) | (1 << 6) |
(1 << 7) | (1 << 8) | (1 << 9) | (1 << 10));
mmio_write(UART0_CR, (1 << 0) | (1 << 8) | (1 << 9));
}
void uart_putc(unsigned char c)
{
while ( mmio_read(UART0_FR) & (1 << 5) ) { }
mmio_write(UART0_DR, c);
}
unsigned char uart_getc()
{
while ( mmio_read(UART0_FR) & (1 << 4) ) { }
return mmio_read(UART0_DR);
}
void uart_puts(const char* str)
{
for (size_t i = 0; str[i] != '\0'; i ++)
uart_putc((unsigned char)str[i]);
}
void kernel_main(uint32_t r0, uint32_t r1, uint32_t atags)
{
(void) r0;
(void) r1;
(void) atags;
uart_init();
uart_puts("Hello, kernel World!\r\n");
while (1) {
uart_putc(uart_getc());
uart_putc('\n');
}
}Pour une explication ligne par ligne de ce code, consultez cette pageUne explication détaillée de kernel.c.
2-3. linker.ld - Attacher les morceaux ensemble▲
Il y a en gros trois Ă©tapes principales dans le processus de compilation CÂ :
- la première est le préprocessing, où toutes vos déclarations #define sont traitées ;
- la seconde étape est la compilation en fichiers objet, où les fichiers individuels de code sont convertis en fichiers binaires appelés fichiers objets ;
- la troisième étape, où ces fichiers individuels sont liés ensemble en un seul fichier exécutable.
Par défaut, GCC lie votre programme comme s'il s'agissait de code niveau utilisateur. Nous devons passer outre les réglages par défaut, car notre noyau n'est pas un programme utilisateur ordinaire. Nous effectuons cela avec un fichier de commandes pour l'éditeur de liens. Voici le script que nous allons utiliser :
linker.ld
ENTRY(_start)
SECTIONS
{
/* DĂ©marre Ă l'adresse de chargement LOADER_ADDR. */
. = 0x8000;
__start = .;
__text_start = .;
.text :
{
KEEP(*(.text.boot))
*(.text)
}
. = ALIGN(4096); /* aligne sur la taille de page */
__text_end = .;
__rodata_start = .;
.rodata :
{
*(.rodata)
}
. = ALIGN(4096); /* aligne sur la taille de page */
__rodata_end = .;
__data_start = .;
.data :
{
*(.data)
}
. = ALIGN(4096); /* aligne sur la taille de page */
__data_end = .;
__bss_start = .;
.bss :
{
bss = .;
*(.bss)
}
. = ALIGN(4096); /* aligne sur la taille de page */
__bss_end = .;
__end = .;
}Pour une explication ligne par ligne de ce code, consultez cette pageUne explication détaillée de linker.ld.
2-4. Compilation et dĂ©marrage▲
Pour compiler ce code pour la VM, nous devons lancer les commandes suivantes :
./gcc-arm-none-eabi-X-XXXX-XX-update/bin/arm-none-eabi-gcc -mcpu=cortex-a7 -fpic -ffreestanding -c boot.S -o boot.o
./gcc-arm-none-eabi-X-XXXX-XX-update/bin/arm-none-eabi-gcc -mcpu=cortex-a7 -fpic -ffreestanding -std=gnu99 -c kernel.c -o kernel.o -O2 -Wall -Wextra
./gcc-arm-none-eabi-X-XXXX-XX-update/bin/arm-none-eabi-gcc -T linker.ld -o myos.elf -ffreestanding -O2 -nostdlib boot.o kernel.oLes deux premières commandes compilent boot.S et kernel.c en code objet. La commande suivante lie ces objets dans un fichier exécutable ELF.
Jetons un œil à ces options peu utilisées de gcc. -mcpu=cortex-a7 signifie que la cible CPU ARM est le cortex-a7, qui est le CPU du Raspberry modèle 2, et que notre VM émule. -fpic correspond à la création de code à position indépendante. Cela signifie que les références aux fonctions, variables, ou symboles doivent être faites relativement à l'instruction courante, et non par une adresse absolue. -ffreestanding signifie que gcc ne peut pas dépendre de la disponibilité de la libc à l'exécution, et qu'il n'y a pas de fonction main comme point d'entrée. -nostdlib indique au linker (éditeur de liens) qu'il ne devrait pas lier l'exécutable à la libc, ce qui est fait par défaut.
Pour lancer le code dans la VM, exécutez la commande suivante :
qemu-system-arm -m 256 -M raspi2 -serial stdio -kernel myos.elfCela lance une VM qui émule le Raspberry Pi modèle 2 avec 256 mégaoctets de mémoire. Elle est réglée pour lire et écrire les données depuis et vers votre terminal normal comme s'il était connecté au RaspBerry Pi à travers une liaison série. La commande spécifie notre noyau en fichier elf en tant que noyau pour lancer la VM.
Après avoir lancé cette VM, vous devriez voir « Hello World » dans votre terminal. Si vous saisissez quelque chose dans votre terminal, il devrait faire un écho de chaque caractère.
Maintenant que nous avons un noyau fonctionnel, nous devrions organiser notre projet.
3. Organiser notre projet▲
Cette section est plus un exercice d'organisation de projet que du développement d'OS. Si cela ne vous intéresse pas, vous devriez aller directement à la partie 4 : gestion de la mémoireGestion de la mémoire.
Si vous voulez télécharger le code et jouer avec, consultez mon dépôt git.
3-1. SĂ©paration de nos fichiers▲
Pour le moment, nous avons notre fichier C, notre fichier pour l'éditeur de liens, nos objets compilés, et notre noyau compilé tout cela dans le même dossier. Avant de commencer à rendre le noyau plus complexe. Ce serait une bonne idée de séparer les différents types de fichiers.
La façon de procéder que nous allons utiliser est de séparer les fichiers C, les en-têtes, et les fichiers de compilation dans des dossiers séparés : src, include, et build. Les dossiers src et include vont être structurés de façon très similaire, donc quand je parle de l'un, comprenez que cela concerne l'autre sauf indication contraire.
src et include vont avoir les dossiers kernel et common, où kernel sera pour les fichiers exclusifs au noyau, et common pour les fichiers qui contiennent des fonctionnalités standard qui ne seront pas exclusives au noyau, comme memcpy.
build va contenir notre fichier pour le linker, et un makefile. Pendant la compilation, le makefile va mettre tous les fichiers objet, ainsi que le binaire compilé du noyau dans le dossier build.
Voici le code du makefile :
# N'utilise pas le gcc normal, utilise le compilateur arm cross-platform
CC = ./gcc-arm-none-eabi-6-2017-q2-update/bin/arm-none-eabi-gcc
# Fixe toute constante basée sur le modèle raspberry pi. La version 1 a quelques différences avec la version 2 et 3
ifeq ($(RASPI_MODEL),1)
CPU = arm1176jzf-s
DIRECTIVES = -D MODEL_1
else
CPU = cortex-a7
endif
CFLAGS= -mcpu=$(CPU) -fpic -ffreestanding $(DIRECTIVES)
CSRCFLAGS= -O2 -Wall -Wextra
LFLAGS= -ffreestanding -O2 -nostdlib
# Emplacement des fichiers
KER_SRC = ../src/kernel
KER_HEAD = ../include
COMMON_SRC = ../src/common
OBJ_DIR = objects
KERSOURCES = $(wildcard $(KER_SRC)/*.c)
COMMONSOURCES = $(wildcard $(COMMON_SRC)/*.c)
ASMSOURCES = $(wildcard $(KER_SRC)/*.S)
OBJECTS = $(patsubst $(KER_SRC)/%.c, $(OBJ_DIR)/%.o, $(KERSOURCES))
OBJECTS += $(patsubst $(COMMON_SRC)/%.c, $(OBJ_DIR)/%.o, $(COMMONSOURCES))
OBJECTS += $(patsubst $(KER_SRC)/%.S, $(OBJ_DIR)/%.o, $(ASMSOURCES))
HEADERS = $(wildcard $(KER_HEAD)/*.h)
IMG_NAME=kernel.img
build: $(OBJECTS) $(HEADERS)
echo $(OBJECTS)
$(CC) -T linker.ld -o $(IMG_NAME) $(LFLAGS) $(OBJECTS)
$(OBJ_DIR)/%.o: $(KER_SRC)/%.c
mkdir -p $(@D)
$(CC) $(CFLAGS) -I$(KER_SRC) -I$(KER_HEAD) -c $< -o $@ $(CSRCFLAGS)
$(OBJ_DIR)/%.o: $(KER_SRC)/%.S
mkdir -p $(@D)
$(CC) $(CFLAGS) -I$(KER_SRC) -c $< -o $@
$(OBJ_DIR)/%.o: $(COMMON_SRC)/%.c
mkdir -p $(@D)
$(CC) $(CFLAGS) -I$(KER_SRC) -I$(KER_HEAD) -c $< -o $@ $(CSRCFLAGS)
clean:
rm -rf $(OBJ_DIR)
rm $(IMG_NAME)
run: build
qemu-system-arm -m 256 -M raspi2 -serial stdio -kernel kernel.imgPour une explication ligne par ligne, consultez cette pageUne explication détaillée sur le makefile.
Cela nous donnera une structure de dossier comme celle-ci :
raspi-kernel/
src/
common/
kernel/
kernel.c
boot.S
include/
common/
kernel/
build/
Makefile
linker.ld3-2. Remaniement de kernel.c▲
Actuellement, kernel.c contient tout le code source pour le noyau entier. Il contient la logique pour configurer l'UART, et pour effectuer les entrées/sorties. Répartissons tout cela dans des fichiers séparés logiquement.
Tout d'abord, nous allons mettre ce gros enumSpécification périphérique et lecture écriture de base depuis kernel.c et qui décrit le périphérique UART et toutes ces signatures de fonction en rapport avec l'UART dans include/kernel/uart.h. Nous allons donc déplacer tout le code concernant l'UART dans src/kernel/uart.c. Cela devrait laisser uniquement la fonction main du noyau.
Nous allons maintenant écrire du code de bibliothèque. Nous créons les fichiers src/common/stdlib.c et src/common/stdio.c et leurs fichiers d'en-tête correspondants.
Dans stdlib.c, nous définissons les fonctions memcpy et bzero, celles-ci seront utiles plus tard, et nous définissons itoa (integer to ascii) pour rendre le débogage plus facile.
Dans stdio.c, nous définissons getc, putc, gets, et puts comme fonctions d'entrées/sorties à usage principal. Nous faisons cela même si uart.c n'a pas encore de fonctions uart_putc et uart_puts, car nous voudrons plus tard échanger uart_putc pour une fonction qui affichera du texte sur l'écran physique, et il sera plus facile de remplacer un appel à uart_putc ici plutôt que dans de multiples emplacements.
L'implémentation de ces fonctions n'est pas importante, si vous voulez vraiment la voir, consultez mon dépôt git.
Notre structure de répertoire ressemble maintenant à ceci ;
raspi-kernel/
src/
common/
stdio.c
stdlib.c
kernel/
kernel.c
boot.S
uart.c
include/
common/
stdio.h
stdlib.h
kernel/
uart.h
build/
Makefile
linker.ldMaintenant que notre projet est raisonnablement organisé, voyons comment gérer la mémoire.
4. Gestion de la mĂ©moire▲
Maintenant que nous pouvons booter et avoir une structure de projet saine, nous pouvons passer au développement du noyau. En tant que noyau, nous pouvons théoriquement utiliser toute la mémoire que nous voulons à tout moment. Pour imposer un certain ordre et pour empêcher de nous tirer une balle dans le pied, nous devons organiser la gestion de la mémoire. La meilleure façon de le faire est de diviser la mémoire en blocs de 4 Ko nommés pages. Les pages nous permettent d'allouer des blocs de mémoire qui ne sont pas insignifiants, mais aussi pas trop gros pour prendre une fraction de mémoire importante.
Si vous voulez télécharger le code et jouer avec vous-même, consultez mon github.
4-1. Obtenir la taille mĂ©moire▲
Si nous voulons organiser toute la mémoire, nous devons connaître la quantité de mémoire à notre disposition. Nous pouvons faire cela en accédant aux AtagsAtags.
Nous pouvons faire correspondre le modèle mémoire des Atags en définissant quelques types C :
typedef enum {
NONE = 0x00000000,
CORE = 0x54410001,
MEM = 0x54410002,
...
} atag_tag_t;
typedef struct {
uint32_t size;
uint32_t start;
} mem_t;
...
typedef struct atag {
uint32_t tag_size;
atag_tag_t tag;
union {
mem_t mem;
...
};
} atag_t;Nous pouvons alors parcourir la liste Atag jusqu'Ă trouver la balise MEMÂ :
uint32_t get_mem_size(atag_t * tag) {
while (tag->tag != NONE) {
if (tag->tag == MEM) {
return tag->mem.size;
}
tag = ((uint32_t *)tag) + tag->tag_size;
}
return 0;
}Si nous développons pour la VM, cela ne fonctionnera pas. La VM n'émule pas le bootloader qui positionne les Atags. Comme nous déterminons la taille mémoire exacte de mémoire à travers les options QEMU, cette fonction devrait juste nous retourner cette quantité. Mon makefile fixe la mémoire à 128 Mo, la fonction devrait donc retourner 1024*1024*128.
4-2. GĂ©rer la mĂ©moire▲
Maintenant que nous pouvons obtenir la taille totale de mémoire, nous pouvons la diviser en pages. Le nombre de pages est simplement la taille mémoire divisée par la taille de page.
Ces pages vont avoir besoin de métadonnées. Elles devront garder la trace de leur allocation ou non, et pour quel usage. Elles auront plus tard besoin de plus de métadonnées quand nous activerons la mémoire virtuelle, voici notre type de métadonnées :
typedef struct {
uint8_t allocated: 1; // Cette page est allouée pour quelque chose
uint8_t kernel_page: 1; // Cette page fait partie du noyau
uint32_t reserved: 30;
} page_flags_t;
typedef struct page {
uint32_t vaddr_mapped; // L'adresse virtuelle qui mappe cette page
page_flags_t flags;
DEFINE_LINK(page);
} page_t;De façon à contenir toutes ces métadonnées, nous réservons une grande partie de la mémoire juste après l'image du noyau pour un tableau de pages de métadonnées. Nous pouvons récupérer cette adresse en utilisant le symbole __end que nous avons déclaré dans le script de l'éditeur de liensUne explication détaillée de linker.ld. Additionnellement, nous allons créer une liste chaînée (implémentation expliquée iciUne explication détaillée sur list.h) pour garder trace des pages libres.
Une fois cela fait, tout ce dont nous avons besoin est de parcourir les pages, initialiser leurs métadonnées et les ajouter à la liste des pages libres.
Voici le code :
extern uint8_t __end;
static uint32_t num_pages;
DEFINE_LIST(page);
IMPLEMENT_LIST(page);
static page_t * all_pages_array;
page_list_t free_pages;
void mem_init(atag_t * atags) {
uint32_t mem_size, page_array_len, kernel_pages, i;
// Obtention du nombre total de pages
mem_size = get_mem_size(atags);
num_pages = mem_size / PAGE_SIZE;
// Allocation de l'espace pour toutes les métadonnées de ces pages. Démarre ce bloc juste après la fin de l'image du noyau
page_array_len = sizeof(page_t) * num_pages;
all_pages_array = (page_t *)&__end;
bzero(all_pages_array, page_array_len);
INITIALIZE_LIST(free_pages);
// Parcourt toutes les pages et les marque avec le drapeau approprié
// Commence avec les pages noyau
kernel_pages = ((uint32_t)&__end) / PAGE_SIZE;
for (i = 0; i < kernel_pages; i++) {
all_pages_array[i].vaddr_mapped = i * PAGE_SIZE; // Identifie les pages noyau
all_pages_array[i].flags.allocated = 1;
all_pages_array[i].flags.kernel_page = 1;
}
// Mappe le reste des pages comme non allouées, et les ajoute à la liste des pages libres
for(; i < num_pages; i++){
all_pages_array[i].flags.allocated = 0;
append_page_list(&free_pages, &all_pages_array[i]);
}
}4-3. Allocation de pages▲
Maintenant que nous avons toutes les pages sous contrôle, ce serait bien de pouvoir allouer et libérer des pages dynamiquement. Cela peut être fait très facilement. Comme les pages font toujours 4 Ko, tout ce que nous avons à faire est de trouver une page qui n'a pas encore été allouée et de retourner un pointeur vers la mémoire. Pour libérer une page, tout ce que nous avons à faire est d'ajouter les métadonnées de page à la liste des pages libres.
Comme les pages ont une taille fixe de 4 Ko, nous pouvons obtenir leur adresse à partir des métadonnées de page en multipliant simplement l'index dans le tableau de page par 4096. Similairement, nous pouvons obtenir les métadonnées depuis la page mémoire en divisant par 4096, et en utilisant cette valeur comme index dans le tableau de pages.
Voici le code :
void * alloc_page(void) {
page_t * page;
void * page_mem;
if (size_page_list(&free_pages) == 0)
return 0;
// Obtention d'une page libre
page = pop_page_list(&free_pages);
page->flags.kernel_page = 1;
page->flags.allocated = 1;
// Obtention de l'adresse physique de la page à laquelle les métadonnées se réfèrent
page_mem = (void *)((page - all_pages_array) * PAGE_SIZE);
// Zero out the page, big security flaw to not do this :)
bzero(page_mem, PAGE_SIZE);
return page_mem;
}
void free_page(void * ptr) {
page_t * page;
// Obtention de la page de métadonnées depuis l'adresse physique
page = all_pages_array + ((uint32_t)ptr / PAGE_SIZE);
// Marque la page libre
page->flags.allocated = 0;
append_page_list(&free_pages, page);
}La capacité d'allouer des pages est une bonne chose, mais la taille stricte de 4 Ko est un peu restrictive pour la plupart des cas d'utilisation. Ensuite, nous allons ajouter à ce code l'implémentation d'un allocateur dynamique de mémoire qui peut nous donner l'allocation d'une taille mémoire de notre choix.
5. Allocateur dynamique de mĂ©moire▲
Dans la partie précédente, nous avons organisé toute la mémoire en pages. Nous allons maintenant réserver un petit bloc de mémoire avec un peu plus de précisions que les 4 Ko.
Si vous voulez télécharger le code et jouer vous-même avec, consultez mon dépôt git.
5-1. Allouer de la mĂ©moire▲
Pour pouvoir allouer de la mémoire, il faut que celle-ci soit déjà allouée ! Comme nous sommes le noyau, nous sommes le patron. Nous pouvons prendre la mémoire directement après les métadonnées de page et la réserver pour le tas (heap). La quantité à réserver est quelque peu arbitraire, j'ai donc choisi 1 Mo, car c'est suffisamment grand pour satisfaire les besoins de mémoire dynamique du noyau, et suffisamment petit pour ne pas pénaliser les allocations mémoire futures du code utilisateur.
Maintenant que nous avons une zone de mémoire substantielle consistante, tout ce que nous voulons, c'est une fonction pour la diviser. Nous voulons proposer l'interface familière void * malloc(uint32_t bytes) dans les fichiers src/kernel/mem.c et include/kernel/mem.h pour cela. Nous allons gérer cela en associant un en-tête à chaque allocation. Les en-têtes formeront une liste chaînée, que nous pourrons facilement parcourir du début d'une allocation à la suivante. Il inclura une taille, et si l'allocation est en cours d'utilisation. Voici la définition de la structure de l'en-tête :
typedef struct heap_segment{
struct heap_segment * next;
struct heap_segment * prev;
uint32_t is_allocated;
uint32_t segment_size; // Inclut cet en-tĂŞte
} heap_segment_t;Pour effectuer une allocation, tout ce que nous avons à faire, c'est de trouver l'allocation qui correspond au mieux aux nombres d'octets demandés et qui n'est pas en cours d'utilisation. Si cette allocation est vraiment importante par rapport à la taille de la demande, nous pouvons diviser cette allocation en deux allocations plus petites, et utiliser seulement l'une d'elles. Le critère que j'ai utilisé pour déterminer si une allocation doit être divisée est si l'allocation est au moins le double de la taille d'un en-tête, car il n'est pas très utile d'avoir de nombreuses allocations qui sont moitié en-tête, moitié données. Une fois que nous avons notre allocation, nous retournons juste un pointeur sur la mémoire directement après l'en-tête. Voici ces idées implémentées dans le code :
void * kmalloc(uint32_t bytes) {
heap_segment_t * curr, *best = NULL;
int diff, best_diff = 0x7fffffff; // taille maximum d 'un entier signé
// Ajoute l'en-tĂŞte au nombre d'octets qu'il nous faut et aligne la taille sur 16 octets
bytes += sizeof(heap_segment_t);
bytes += bytes % 16 ? 16 - (bytes % 16) : 0;
// Trouve l'allocation la plus proche de la taille requise
for (curr = heap_segment_list_head; curr != NULL; curr = curr->next) {
diff = curr->segment_size - bytes;
if (!curr->is_allocated && diff < best_diff && diff >= 0) {
best = curr;
best_diff = diff;
}
}
// Il ne doit pas y avoir de mémoire libre maintenant :(
if (best == NULL)
return NULL;
// Si la meilleure différence est plus grosse, division de ce segment en deux autres.
// Comme nos en-têtes de segment sont plutôt larges, le critère de division est que
// lors de la division, le segment non requis doit ĂŞtre deux fois plus large que la taille d'un en-tĂŞte
if (best_diff > (int)(2 * sizeof(heap_segment_t))) {
bzero(((void*)(best)) + bytes, sizeof(heap_segment_t));
curr = best->next;
best->next = ((void*)(best)) + bytes;
best->next->next = curr;
best->next->prev = best;
best->next->segment_size = best->segment_size - bytes;
best->segment_size = bytes;
}
best->is_allocated = 1;
return best + 1;
}5-2. LibĂ©rer la mĂ©moire▲
Maintenant que nous avons malloc, nous avons naturellement besoin de free pour que le mégaoctet de données que nous n'avons pas utilisé puisse être libéré. Bien sûr, nous devons marquer les allocations comme non utilisées, pour qu'un autre appel à malloc puisse les redistribuer. De plus, nous devons regrouper les allocations libres adjacentes en une seule zone plus grande. Voici le code :
void kfree(void *ptr) {
heap_segment_t * seg = ptr - sizeof(heap_segment_t);
seg->is_allocated = 0;
// Essaye de regrouper avec le segment de gauche
while(seg->prev != NULL && !seg->prev->is_allocated) {
seg->prev->next = seg->next;
seg->prev->segment_size += seg->segment_size;
seg = seg->prev;
}
// Essaye de regrouper avec le segment de droite
while(seg->next != NULL && !seg->next->is_allocated) {
seg->segment_size += seg->next->segment_size;
seg->next = seg->next->next;
}
}5-3. Initialisation du tas (heap)▲
Maintenant que nous avons les algorithmes, nous devons les initialiser. Pour effectuer cela, nous devons réserver les pages que nous allons utiliser, mettre un en-tête au début de notre allocation de 1 Mo qui dit qu'il y a 1 Mo d'inutilisé à cet endroit, et attribuer heap_segment_list_head à cet en-tête. Finalement, nous devons appeler cette fonction d'initialisation dans la fonction main du noyau. Voici le code :
static heap_segment_t * heap_segment_list_head;
void mem_init(void) {
...
kernel_pages = ((uint32_t)&__end) / PAGE_SIZE;
for (i = 0; i < kernel_pages; i++) {
all_pages_array[i].vaddr_mapped = i * PAGE_SIZE; // carte d'identité des pages noyau
all_pages_array[i].flags.allocated = 1;
all_pages_array[i].flags.kernel_page = 1;
}
// RĂ©serve 1 Mo pour le tas du noyau
for(; i < kernel_pages + (KERNEL_HEAP_SIZE / PAGE_SIZE); i++){
all_pages_array[i].vaddr_mapped = i * PAGE_SIZE; // carte d'identité des pages noyau
all_pages_array[i].flags.allocated = 1;
all_pages_array[i].flags.kernel_heap_page = 1;
}
// Mappe le reste des pages comme non allouées, et les ajoute à la liste des pages libres.
for(; i < num_pages; i++){
all_pages_array[i].flags.allocated = 0;
append_page_list(&free_pages, &all_pages_array[i]);
}
// Initialise le tas
page_array_end = (uint32_t)&__end + page_array_len;
heap_init(page_array_end)
}
static void heap_init(uint32_t heap_start) {
heap_segment_list_head = (heap_segment_t *) heap_start;
bzero(heap_segment_list_head, sizeof(heap_segment_t));
heap_segment_list_head->segment_size = KERNEL_HEAP_SIZE;
}Nous allons ensuite faire afficher notre noyau sur un vrai Ă©cran.
6. Affichage sur un Ă©cran rĂ©el▲
À partir de maintenant, notre noyau peut effectuer des entrées/sorties à travers son port série. Sur du matériel réel, nous attendons que les sorties soient affichées sur un écran réel, habituellement à travers l'HDMI, pas à travers une connexion série spécialisée. Dans cette partie, nous allons voir comment atteindre cet objectif.
Si vous voulez télécharger le code et jouer vous-même avec, consultez mon dépôt git.
6-1. Obtention d'un framebuffer▲
Si vous n'ĂŞtes pas familier avec le concept de framebuffers, je vous recommande la lecture de Framebuffer, pas et profondeurFramebuffer, pas, et profondeur avant de continuer.
Pour pouvoir dessiner quelque chose à l'écran, nous devons obtenir un framebuffer. Nous ne pouvons en obtenir un qu'en le demandant très gentiment au GPU. Ce processus diffère entre les modèles Raspberry Pi 1 et 2. Puisque je développe pour une VM modèle 1 et 2, je vais parler des deux.
Les deux appareils obtiennent un framebuffer en utilisant le périphérique mailbox. Consultez le périphérique MailboxLe périphérique Mailbox pour voir les détails du fonctionnement de la mailbox et les interfaces dont elle dispose.
Pour les deux méthodes, nous allons utiliser un simple fichier d'en-tête, include/kernel/framebuffer.h, qui va déclarer une structure pour gérer les informations à propos de notre framebuffer, une instance globale de cette structure, et une fonction framebuffer_init qui l'initialisera. Pour construire ceci, nous allons modifier le makefile comme ci-dessous :
...
ifeq ($(RASPI_MODEL),1)
CPU = arm1176jzf-s
DIRECTIVES = -D MODEL_1
ARCHDIR = model1
else
CPU = cortex-a7
ARCHDIR = model2
endif
...
KERSOURCES += $(wildcard $(KER_SRC)/$(ARCHDIR)/*.c)
...
$(OBJ_DIR)/%.o: $(KER_SRC)/$(ARCHDIR)/%.c
mkdir -p $(@D)
$(CC) $(CFLAGS) -I$(KER_SRC) -I$(KER_HEAD) -c $< -o $@ $(CSRCFLAGS)Maintenant, make choisira l'implémentation correcte selon que RASPI_MODEL=1 ou non.
6-1-1. Initialisation du framebuffer sur le modèle 1▲
Pour obtenir un framebuffer sur le modèle 1, nous devons utiliser le framework mailbox channelcette pageLe Framebuffer Mailbox Channel. Le seul but de ce canal est d'initialiser un framebuffer. Les détails de l'utilisation de la mailbox sont décrits dans cette pageLe Framebuffer Mailbox Channel, nous nous intéresserons ici à l'implémentation.
Une fois le framebuffer obtenu de la mailbox, nous remplissons la structure d'informations globales fbinfo, avec la largeur, la hauteur, et la profondeur que nous avons utilisées pour initialiser le framebuffer. Nous mettons également le pitchFramebuffer, pas, et profondeur, le pointeur vers le framebuffer, sa taille, la largeur et hauteur de l'écran en caractères, et la position du curseur. Ces deux derniers champs seront importants quand nous afficherons des caractères au lieu de simples pixels.
Voici le code :
typedef struct {
uint32_t width;
uint32_t height;
uint32_t vwidth;
uint32_t vheight;
uint32_t bytes;
uint32_t depth;
uint32_t ignorex;
uint32_t ignorey;
void * pointer;;
uint32_t size;
} fb_init_t;
fb_init_t fbinit __attribute__((aligned(16)));
int framebuffer_init(void) {
mail_message_t msg;
fbinit.width = 640;
fbinit.height = 480;
fbinit.vwidth = fbinit.width;
fbinit.vheight = fbinit.height;
fbinit.depth = COLORDEPTH;
msg.data = ((uint32_t)&fbinit + 0x40000000) >> 4;
mailbox_send(msg, FRAMEBUFFER_CHANNEL);
msg = mailbox_read(FRAMEBUFFER_CHANNEL);
if (!msg.data)
return -1;
fbinfo.width = fbinit.width;
fbinfo.height = fbinit.height;
fbinfo.chars_width = fbinfo.width / CHAR_WIDTH;
fbinfo.chars_height = fbinfo.height / CHAR_HEIGHT;
fbinfo.chars_x = 0;
fbinfo.chars_y = 0;
fbinfo.pitch = fbinit.bytes;
fbinfo.buf = fbinit.pointer;
fbinfo.buf_size = fbinit.size;
return 0;
}6-2. Initialisation du framebuffer sur le modèle 2 et plus▲
Pour obtenir un framebuffer sur le modèle 2 et plus, nous devons utiliser le property mailbox channel channelLe property mailbox channel. Ce canal a d'autres buts que celui d'obtenir un framebuffer, le code pour l'utiliser est donc plus abstrait que pour le canal framebuffer. Comme avant, les détails d'utilisation de property channel pour obtenir un framebuffer sont exposés sur cette pageLe property mailbox channel, nous ne parlerons donc ici que de l'implémentation.
Comme la property interface est plus abstraite, les définitions de drapeaux et de l'implémentation de l'envoi et réception de messages sont faites dans include/kernel/mailbox.h et src/kernel/mailbox.c. Nous définissons une interface send_message(property_message_tag_t * tags), qui prend un tableau de messages drapeau terminé par NULL, les empaquette dans le format approprié, envoie le message, récupère la réponse, et retourne chaque réponse de drapeau dans le tableau donné.
property_message_tag_t et les définitions afférentes sont présentées ci-dessous :
typedef enum {
NULL_TAG = 0,
FB_ALLOCATE_BUFFER = 0x00040001,
FB_RELESE_BUFFER = 0x00048001,
FB_GET_PHYSICAL_DIMENSIONS = 0x00040003,
FB_SET_PHYSICAL_DIMENSIONS = 0x00048003,
FB_GET_VIRTUAL_DIMENSIONS = 0x00040004,
FB_SET_VIRTUAL_DIMENSIONS = 0x00048004,
FB_GET_BITS_PER_PIXEL = 0x00040005,
FB_SET_BITS_PER_PIXEL = 0x00048005,
FB_GET_BYTES_PER_ROW = 0x00040008
} property_tag_t;
typedef struct {
void * fb_addr;
uint32_t fb_size;
} fb_allocate_res_t;
typedef struct {
uint32_t width;
uint32_t height;
} fb_screen_size_t;
/*
* La valeur buffer peut ĂŞtre de n'importe lequel de ces types
*/
typedef union {
uint32_t fb_allocate_align;
fb_allocate_res_t fb_allocate_res;
fb_screen_size_t fb_screen_size;
uint32_t fb_bits_per_pixel;
uint32_t fb_bytes_per_row;
} value_buffer_t;
/*
* Un buffer message_peut contenir n'importe lequel de ces types
*/
typedef struct {
property_tag_t proptag;
value_buffer_t value_buffer;
} property_message_tag_t;Le code utilisé pour empaqueter un tableau de ces drapeaux dans le format approprié n'est qu'une simple implémentation du format décrit iciLe property mailbox channel. La fonction get_value_buffer_len code simplement en dur les différentes valeurs de taille de buffer pour chaque drapeau défini.
Voici le code :
static uint32_t get_value_buffer_len(property_message_tag_t * tag) {
switch(tag->proptag) {
case FB_ALLOCATE_BUFFER:
case FB_GET_PHYSICAL_DIMENSIONS:
case FB_SET_PHYSICAL_DIMENSIONS:
case FB_GET_VIRTUAL_DIMENSIONS:
case FB_SET_VIRTUAL_DIMENSIONS:
return 8;
case FB_GET_BITS_PER_PIXEL:
case FB_SET_BITS_PER_PIXEL:
case FB_GET_BYTES_PER_ROW:
return 4;
case FB_RELESE_BUFFER:
default:
return 0;
}
}
int send_messages(property_message_tag_t * tags) {
property_message_buffer_t * msg;
mail_message_t mail;
uint32_t bufsize = 0, i, len, bufpos;
// Calcule les tailles de chaque drapeau
for (i = 0; tags[i].proptag != NULL_TAG; i++) {
bufsize += get_value_buffer_len(&tags[i]) + 3*sizeof(uint32_t);
}
// Ajoute la taille de buffer, le code rquête/réponse du buffer et le drapeau de fin de taille
bufsize += 3*sizeof(uint32_t);
// la taille de buffer doit être alignée sur 16 octets
bufsize += (bufsize % 16) ? 16 - (bufsize % 16) : 0;
// kmalloc retourne une adresse alignée sur 16 octets
msg = kmalloc(bufsize);
if (!msg)
return -1;
msg->size = bufsize;
msg->req_res_code = REQUEST;
// Copie les messages dans le buffer
for (i = 0, bufpos = 0; tags[i].proptag != NULL_TAG; i++) {
len = get_value_buffer_len(&tags[i]);
msg->tags[bufpos++] = tags[i].proptag;
msg->tags[bufpos++] = len;
msg->tags[bufpos++] = 0;
memcpy(msg->tags+bufpos, &tags[i].value_buffer, len);
bufpos += len/4;
}
msg->tags[bufpos] = 0;
// Envoie le message
mail.data = ((uint32_t)msg) >>4;
mailbox_send(mail, PROPERTY_CHANNEL);
mail = mailbox_read(PROPERTY_CHANNEL);
if (msg->req_res_code == REQUEST) {
kfree(msg);
return 1;
}
// Vérifie le code de réponse
if (msg->req_res_code == RESPONSE_ERROR) {
kfree(msg);
return 2;
}
// Retourne les drapeaux dans le tableau
for (i = 0, bufpos = 0; tags[i].proptag != NULL_TAG; i++) {
len = get_value_buffer_len(&tags[i]);
bufpos += 3; //skip over the tag bookkepping info
memcpy(&tags[i].value_buffer, msg->tags+bufpos,len);
bufpos += len/4;
}
kfree(msg);
return 0;
}Avec ce code, tout ce que src/kernel/model2/framebuffer.c doit faire, c'est de créer un tableau de ces drapeaux, les passer à send_message, et placer l'information résultante dans la structure d'informations globale, fbinfo.
Voici le code :
int framebuffer_init(void) {
property_message_tag_t tags[5];
tags[0].proptag = FB_SET_PHYSICAL_DIMENSIONS;
tags[0].value_buffer.fb_screen_size.width = 640;
tags[0].value_buffer.fb_screen_size.height = 480;
tags[1].proptag = FB_SET_VIRTUAL_DIMENSIONS;
tags[1].value_buffer.fb_screen_size.width = 640;
tags[1].value_buffer.fb_screen_size.height = 480;
tags[2].proptag = FB_SET_BITS_PER_PIXEL;
tags[2].value_buffer.fb_bits_per_pixel = COLORDEPTH;
tags[3].proptag = NULL_TAG;
// Envoie l'initialisation
if (send_messages(tags) != 0) {
return -1;
}
fbinfo.width = tags[0].value_buffer.fb_screen_size.width;
fbinfo.height = tags[0].value_buffer.fb_screen_size.height;
fbinfo.chars_width = fbinfo.width / CHAR_WIDTH;
fbinfo.chars_height = fbinfo.height / CHAR_HEIGHT;
fbinfo.chars_x = 0;
fbinfo.chars_y = 0;
fbinfo.pitch = fbinfo.width*BYTES_PER_PIXEL;
// requĂŞte d'un framebuffer
tags[0].proptag = FB_ALLOCATE_BUFFER;
tags[0].value_buffer.fb_screen_size.width = 0;
tags[0].value_buffer.fb_screen_size.height = 0;
tags[0].value_buffer.fb_allocate_align = 16;
tags[1].proptag = NULL_TAG;
if (send_messages(tags) != 0) {
return -1;
}
fbinfo.buf = tags[0].value_buffer.fb_allocate_res.fb_addr;
fbinfo.buf_size = tags[0].value_buffer.fb_allocate_res.fb_size;
return 0;
}6-3. Afficher des caractères▲
Après l'obtention d'un framebuffer, nous voulons être capable d'y dessiner facilement. Nous allons définir src/kernel/gpu.c et include/kernel/gpu.h pour définir et implémenter le dessin sur l'écran. Nous allons exposer trois fonctions : gpu_init(void), write_pixel(void write_pixel(uint32_t x, uint32_t y, const pixel_t * pixel), et gpu_putc(char c).
gpu_init initialise simplement l'Ă©cran en appelant framebuffer_init() et en noircissant l'Ă©cran.
write_pixel colore le pixel aux coordonnées communiquées. Voici la définition de pixel_t et l'implémentation de write_pixel :
typedef struct pixel {
uint8_t red;
uint8_t green;
uint8_t blue;
} pixel_t;
...
void write_pixel(uint32_t x, uint32_t y, const pixel_t * pix) {
uint8_t * location = fbinfo.buf + y*fbinfo.pitch + x*BYTES_PER_PIXEL;
memcpy(location, pix, BYTES_PER_PIXEL);
}De façon à dessiner un caractère, nous avons besoin des bitmaps de chaque caractère que nous voulons afficher. Le type de bitmaps choisi détermine la police de caractères. Voici les bitmaps utilisésBitmap police de caractères. C'est un tableau 2D, avec 128 éléments de huit tableaux d'entiers de 8 bits non signés, créant un bitmap de 8x8 par caractère. Ceci peut être facilement remplacé par une autre police si vous le souhaitez.
Si vous regardez ma bitmap, j'ai fait quelque chose d'étrange. Plutôt que de faire en sorte d'avoir un tableau global, c'est un tableau statique dans une fonction. C'est une solution de contournement d'un problème où un tableau global n'est pas inclus lors de la compilation sur une vraie machine. Malheureusement, je ne suis pas encore sûr de la cause du problème, mais cette façon étrange d'accéder aux bitmaps le contourne suffisamment bien.
Nous avons maintenant des bitmaps de caractères, et pouvons donc implémenter gpu_putc, voici le code :
void gpu_putc(char c) {
static const pixel_t WHITE = {0xff, 0xff, 0xff};
static const pixel_t BLACK = {0x00, 0x00, 0x00};
uint8_t w,h;
uint8_t mask;
const uint8_t * bmp = font(c);
uint32_t i, num_rows = fbinfo.height/CHAR_HEIGHT;
// décale tout d'une ligne vers le haut
if (fbinfo.chars_y >= num_rows) {
// copie une ligne complète vers la ligne située au dessus
for (i = 0; i < num_rows-1; i++)
memcpy(fbinfo.buf + fbinfo.pitch*i*CHAR_HEIGHT, fbinfo.buf + fbinfo.pitch*(i+1)*CHAR_HEIGHT, fbinfo.pitch * CHAR_HEIGHT);
// met à zéro la dernière ligne
bzero(fbinfo.buf + fbinfo.pitch*i*CHAR_HEIGHT,fbinfo.pitch * CHAR_HEIGHT);
fbinfo.chars_y--;
}
if (c == '\n') {
fbinfo.chars_x = 0;
fbinfo.chars_y++;
return;
}
for(w = 0; w < CHAR_WIDTH; w++) {
for(h = 0; h < CHAR_HEIGHT; h++) {
mask = 1 << (w);
if (bmp[h] & mask)
write_pixel(fbinfo.chars_x*CHAR_WIDTH + w, fbinfo.chars_y*CHAR_HEIGHT + h, &WHITE);
else
write_pixel(fbinfo.chars_x*CHAR_WIDTH + w, fbinfo.chars_y*CHAR_HEIGHT + h, &BLACK);
}
}
fbinfo.chars_x++;
if (fbinfo.chars_x > fbinfo.chars_width) {
fbinfo.chars_x = 0;
fbinfo.chars_y++;
}
}Tout ce dont nous avons besoin maintenant, c'est de remplacer uart_putc avec gpu_putc dans notre implémentation de putc, et nous pouvons maintenant imprimer sur un vrai écran. Voici à quoi cela devrait ressembler :
|
|
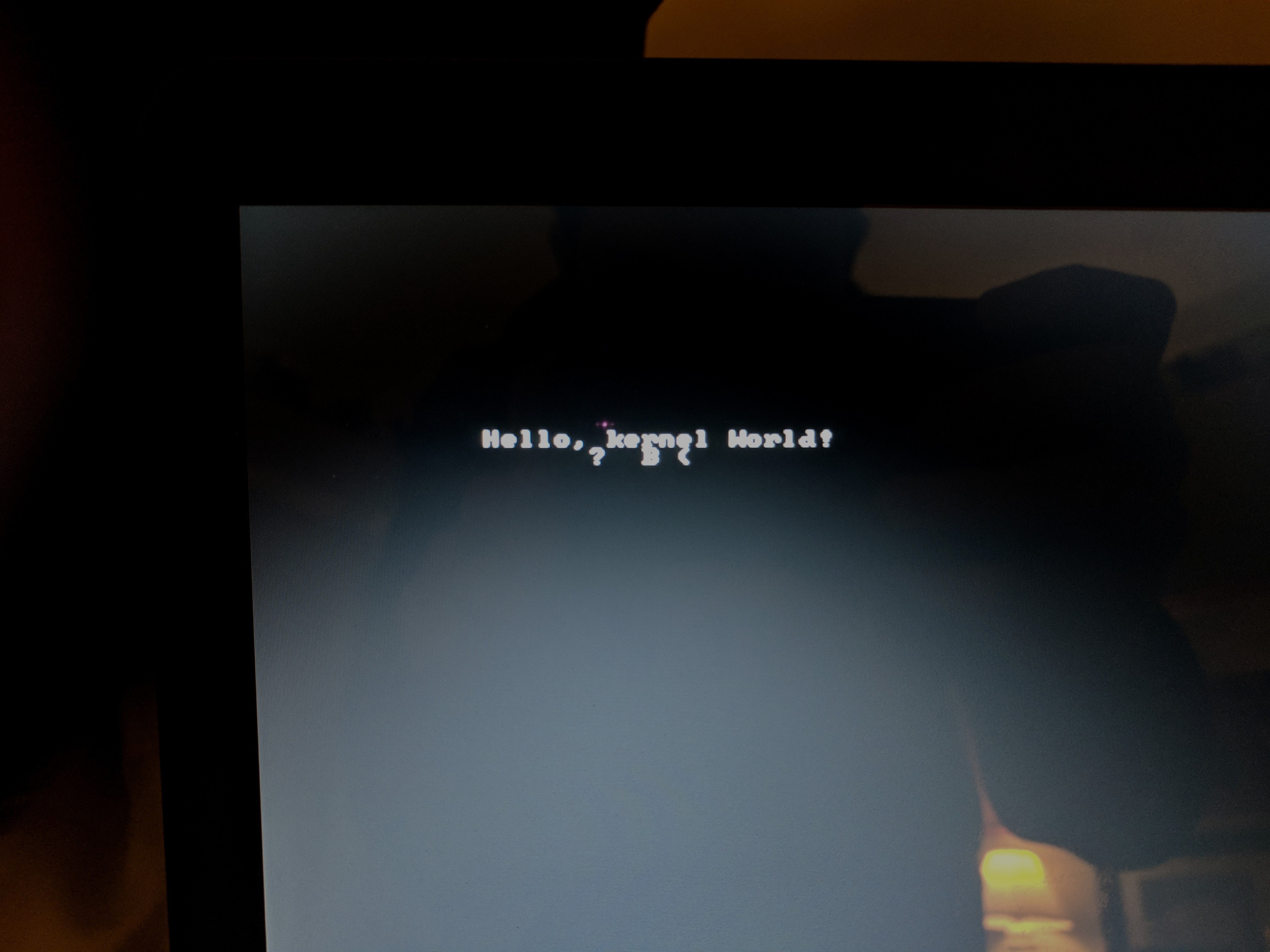
Pour découvrir comment charger votre noyau sur une vraie machine, consultez cette pageCharger le noyau dans du vrai matériel.
La prochaine étape sera de pouvoir exécuter plusieurs processus, mais avant de pouvoir faire cela, il nous faut configurer un système appelé interruptions.
7. Les interruptions▲
La prochaine chose la plus utile est de lancer des processus. De façon à pouvoir le faire, nous devons d'abord configurer les exceptions et les interruptions. Si vous n'êtes pas familier avec ces concepts, consultez cette pageInterruptions et exceptions.
Si vous voulez télécharger le code et le tester par vous-même, consultez mon dépôt git.
7-1. Configurer la table des vecteurs d'exception▲
Avant de pouvoir gérer les IRQ, nous devons configurer les gestionnaires d'exceptions, et configurer la table des vecteurs d'exceptionInterruptions et exceptions pour y accéder.
Les gestionnaires d'exceptions sont des fonctions, mais ils ne peuvent pas être des fonctions normales, car les gestionnaires d'exceptions ont besoin de prologues et d'épilogues plus avancés qu'une fonction normale. Notre compilateur peut gérer cela pour nous en utilisant un attribut. Voici à quoi une signature de gestionnaire d'IRQ doit ressembler :
void __attribute__ ((interrupt ("SWI"))) software_interrupt_handler(void);Où « SWI » devrait être remplacé par « IRQ » pour un gestionnaire d'interruptions, « FIQ » pour un gestionnaire FIQ, « ABORT » pour le reset, l'Annulation Data, et les gestionnaires Prefetch Abort, et « UNDEF » pour le gestionnaire d'instructions non définies. Nous voulons avoir des gestionnaires définis pour toutes les exceptions, même si nous ne savons pas encore vraiment quoi faire avec. Pour le moment, déclarons-les dans src/kernel/interrupt.c comme fonctions factices comme ci-dessous :
void irq_handler(void) {
printf("IRQ HANDLER\n");
while(1);
}
void __attribute__ ((interrupt ("ABORT"))) reset_handler(void) {
printf("RESET HANDLER\n");
while(1);
}
void __attribute__ ((interrupt ("ABORT"))) prefetch_abort_handler(void) {
printf("PREFETCH ABORT HANDLER\n");
while(1);
}
void __attribute__ ((interrupt ("ABORT"))) data_abort_handler(void) {
printf("DATA ABORT HANDLER\n");
while(1);
}
void __attribute__ ((interrupt ("UNDEF"))) undefined_instruction_handler(void) {
printf("UNDEFINED INSTRUCTION HANDLER\n");
while(1);
}
void __attribute__ ((interrupt ("SWI"))) software_interrupt_handler(void) {
printf("SWI HANDLER\n");
while(1);
}
void __attribute__ ((interrupt ("FIQ"))) fast_irq_handler(void) {
printf("FIQ HANDLER\n");
while(1);
}C'est la façon simple et rapide de définir des gestionnaires d'exceptions dont nous ne nous préoccupons pas encore. Nous n'incluons pas d'attribut sur le gestionnaire d'IRQ, car nous voulons avoir un gestionnaire personnalisé en assembleur qui appellera irq_handler.
Nous avons maintenant défini les gestionnaires, nous pouvons configurer la table d'exceptions. Cela est entièrement fait en assembleur pour éviter que gcc « optimise » l'accès à l'adresse mémoire 0. Voici le code :
.section ".text"
.global move_exception_vector
exception_vector:
ldr pc, reset_handler_abs_addr
ldr pc, undefined_instruction_handler_abs_addr
ldr pc, software_interrupt_handler_abs_addr
ldr pc, prefetch_abort_handler_abs_addr
ldr pc, data_abort_handler_abs_addr
nop // Celui-ci est réservé
ldr pc, irq_handler_abs_addr
ldr pc, fast_irq_handler_abs_addr
reset_handler_abs_addr: .word reset_handler
undefined_instruction_handler_abs_addr: .word undefined_instruction_handler
software_interrupt_handler_abs_addr: .word software_interrupt_handler
prefetch_abort_handler_abs_addr: .word prefetch_abort_handler
data_abort_handler_abs_addr: .word data_abort_handler
irq_handler_abs_addr: .word irq_handler_asm_wrapper
fast_irq_handler_abs_addr: .word fast_irq_handler
move_exception_vector:
push {r4, r5, r6, r7, r8, r9}
ldr r1, =exception_vector
mov r1, #0x0000
ldmia r0!,{r2, r3, r4, r5, r6, r7, r8, r9}
stmia r1!,{r2, r3, r4, r5, r6, r7, r8, r9}
ldmia r0!,{r2, r3, r4, r5, r6, r7, r8}
stmia r1!,{r2, r3, r4, r5, r6, r7, r8}
pop {r4, r5, r6, r7, r8, r9}
blx lr
irq_handler_asm_wrapper:
sub lr, lr, #4
srsdb sp!, #0x13
cpsid if, #0x13
push {r0-r3, r12, lr}
and r1, sp, #4
sub sp, sp, r1
push {r1}
bl irq_handler
pop {r1}
add sp, sp, r1
pop {r0-r3, r12, lr}
rfeia sp!Il y a trop à expliquer sur ce code, celui-ci est détaillé dans cette pageUne explication détaillée d'interrupt_vector.S.
7-2. GĂ©rer les IRQ▲
Maintenant que nous avons configuré le gestionnaire d'exceptions des IRQ, nous devons ajouter la possibilité de détecter quelle IRQ a été déclenchée, et sa gestion. Pour faire cela, nous devrons lire et écrire sur le périphérique IRQSpécification périphérique et lecture écriture de base. Nous pouvons facilement accomplir cela avec une structure C :
typedef struct {
uint32_t irq_basic_pending;
uint32_t irq_gpu_pending1;
uint32_t irq_gpu_pending2;
uint32_t fiq_control;
uint32_t irq_gpu_enable1;
uint32_t irq_gpu_enable2;
uint32_t irq_basic_enable;
uint32_t irq_gpu_disable1;
uint32_t irq_gpu_disable2;
} interrupt_registers_t;Pour chaque IRQ possible, nous voudrons avoir une fonction de gestion spécialisée. Plutôt que d'écrire chaque gestionnaire spécialisé dans un fichier interrupts.c, nous allons exposer une interface pour déclarer les gestionnaires d'interruptions en dehors de interrupts.c. Tout d'abord, nous définissons le type de gestionnaire d'interruptions :
typedef void (*interrupt_handler_f)(void);C'est un pointeur vers une fonction qui n'a pas de paramètre et pas de valeur de retour. Nous pouvons alors stocker un tableau de ces pointeurs de fonctions dans interrupt.c. Comme il y a trois mots de quatre octets représentant les interruptions possibles, mais que les trois octets d'interruptions de base sont répétés sur les autres, il y a 72 interruptions différentes qui pourraient être gérées, nous déclarons donc un tableau de 72 gestionnaires.
static interrupt_handler_f handlers[72];La documentation du Raspberry Pi dit que le drapeau « interrupt Pending » (interruption en attente) ne peut pas être effacé en utilisant le périphérique d'interruption. Il doit être effacé en utilisant le périphérique matériel qui a déclenché l'interruption. Pour cette raison, nous voudrons également que les utilisateurs déclarent une fonction d'effacement spécialisée pour ce type particulier d'interruption :
typedef void (*interrupt_clearer_f)(void);
...
static interrupt_clearer_f clearers[72];Pour déclarer un gestionnaire, nous utilisons le code suivant :
void register_irq_handler(irq_number_t irq_num, interrupt_handler_f handler, interrupt_clearer_f clearer) {
uint32_t irq_pos;
if (IRQ_IS_BASIC(irq_num)) {
irq_pos = irq_num - 64;
handlers[irq_num] = handler;
clearers[irq_num] = clearer;
interrupt_regs->irq_basic_enable |= (1 << irq_pos);
}
else if (IRQ_IS_GPU2(irq_num)) {
irq_pos = irq_num - 32;
handlers[irq_num] = handler;
clearers[irq_num] = clearer;
interrupt_regs->irq_gpu_enable2 |= (1 << irq_pos);
}
else if (IRQ_IS_GPU1(irq_num)) {
irq_pos = irq_num;
handlers[irq_num] = handler;
clearers[irq_num] = clearer;
interrupt_regs->irq_gpu_enable1 |= (1 << irq_pos);
}
}Où IRQ_IS_BASIC, IRQ_IS_GPU1, et IRQ_IS_GPU2 sont des macros qui contrôlent si le numéro d'IRQ est dans cette plage, et que irq_number_t est un enum qui nomme chaque numéro d'interruption.
Afin de vérifier quelle IRQ a été déclenchée et d'exécuter le gestionnaire, nous devons contrôler les bits activés du périphérique d'IRQ, et exécuter en conséquence le gestionnaire adéquat :
void irq_handler(void) {
int j;
for (j = 0; j < NUM_IRQS; j++) {
// Si l'interruption est en attente et qu'il y a un gestionnaire, on le lance
if (IRQ_IS_PENDING(interrupt_regs, j) && (handlers[j] != 0)) {
clearers[j]();
ENABLE_INTERRUPTS();
handlers[j]();
DISABLE_INTERRUPTS();
return;
}
}
}Ce code fait simplement une itération sur tous les drapeaux irq pending. Si une interruption est en attente et qu'il y a un gestionnaire correspondant, le nettoyeur est appelé, les interruptions sont alors activées et autorisées pour l' « imbrication » des interruptions, le gestionnaire est appelé et les interruptions sont désactivées pour finir celle-ci.
7-3. Initialiser les interruptions▲
Nous avons maintenant en place toute l'infrastructure nécessaire pour gérer les interruptions. Tout ce que nous avons à faire est de l'initialiser. Voici le code pour le faire :
static interrupt_registers_t * interrupt_regs;
static interrupt_handler_f handlers[72];
static interrupt_clearer_f clearers[72];
extern void move_exception_vector(void);
void interrupts_init(void) {
interrupt_regs = (interrupt_registers_t *)INTERRUPTS_PENDING;
bzero(handlers, sizeof(interrupt_handler_f) * NUM_IRQS);
bzero(clearers, sizeof(interrupt_clearer_f) * NUM_IRQS);
interrupt_regs->irq_basic_disable = 0xffffffff; // disable all interrupts
interrupt_regs->irq_gpu_disable1 = 0xffffffff;
interrupt_regs->irq_gpu_disable2 = 0xffffffff;
move_exception_vector();
ENABLE_INTERRUPTS();
}Ceci initialise d'abord la structure interrupt register, puis met à zéro tous les gestionnaires, désactive toutes les interruptions, comme nous voulons les activer au fur et à mesure de leur enregistrement, puis enfin appelons move_exception_vector définie dans interrupt_vector.S pour copier la table de vecteurs d'exception à l'adresse 0. Nous activons finalement les interruptions.
ENABLE_INTERRUPTS et DISABLE_INTERRUPTS (non appelés ici) sont des fonctions « en ligne » (inline functions) qui seront fréquemment appelées quand nous ajouterons plus de fonctionnalités. Voici le code :
__inline__ int INTERRUPTS_ENABLED(void) {
int res;
__asm__ __volatile__("mrs %[res], CPSR": [res] "=r" (res)::);
return ((res >> 7) & 1) == 0;
}
__inline__ void ENABLE_INTERRUPTS(void) {
if (!INTERRUPTS_ENABLED()) {
__asm__ __volatile__("cpsie i");
}
}INTERRUPTS_ENABLED charge le Program Status Register courant, ou CPSR dans un registre. Il contrôle ensuite le bit 7. Si le bit 7 est effacé, alors les interruptions sont activées. ENABLE_INTERRUPTS exécute l'instruction cps (Change Processor State) avec ie (Interrupts Enable) activé. L'argument i correspond à « enable IRQ » en opposition à f pour FIQ. DISABLE_INTERRUPTS fonctionne exactement comme ENABLE_INTERRUPTS, à l'exception du suffixe id (Interrupts Disable).
7-4. Le timer système▲
Les interruptions sont inutiles à moins d'avoir quelque chose qui les déclenche. Nous allons paramétrer le périphérique timer systèmeLe périphérique système timer, car cela sera utile pour configurer deux processus.
Nous déclarons une structure C pour mapper le périphérique timer système :
typedef struct {
uint8_t timer0_matched: 1;
uint8_t timer1_matched: 1;
uint8_t timer2_matched: 1;
uint8_t timer3_matched: 1;
uint32_t reserved: 28;
} timer_control_reg_t;
typedef struct {
timer_control_reg_t control;
uint32_t counter_low;
uint32_t counter_high;
uint32_t timer0;
uint32_t timer1;
uint32_t timer2;
uint32_t timer3;
} timer_registers_t;Nous allons ensuite définir un gestionnaire d'interruptions et un nettoyeur. Nous n'en avons pas besoin pour faire quelque chose de complexe pour le moment. Nous voulons juste nous assurer qu'il fonctionne :
static timer_registers_t * timer_regs;
static void timer_irq_handler(void) {
printf("timeout :)\n");
timer_set(3000000);
}
static void timer_irq_clearer(void) {
timer_regs->control.timer1_matched = 1;
}Nous ne faisons ici qu'afficher quelque chose et remettre le timer à zéro. Il ne reste plus qu'à enregistrer cette fonction dans le système d'interruption :
void timer_init(void) {
timer_regs = (timer_registers_t *) SYSTEM_TIMER_BASE;
register_irq_handler(SYSTEM_TIMER_1, timer_irq_handler, timer_irq_clearer);
}Nous pouvons maintenant ajouter dans kernel_main :
...
mem_init();
interrupts_init();
timer_init();
timer_set(1000000); // 1 second
puts("Hello, kernel World!\n");
...pour voir notre interruption timer en action.
Nous allons ensuite voir comment avoir un autre processus actif.
Pour les lecteurs utilisant une VMÂ :
au moment de l'écriture de ce tutoriel, l'implémentation QEMU du modèle Raspberry Pi 2 n'a pas de système timer implémenté. Par conséquent, cette partie et celles s'appuyant dessus ne fonctionneront pas dans une VM.
8. Processus▲
Une des plus importantes responsabilités du noyau est de fournir une interface pour démarrer les processus, et de commuter entre eux. Nous devons pouvoir stopper un processus, sauver son état, en démarrer un autre, et restaurer le premier processus plus tard sans qu'il réalise qu'il n'était pas en cours d'exécution.
Si vous voulez télécharger le code et le tester par vous-même, consultez mon dépôt git.
8-1. Le Process Control Block▲
Le Process Control Block (ou PCB) est la structure de données qui gère toutes les informations concernant un processus quand il n'est pas en cours d'exécution afin qu'il puisse être restauré. C'est ce qui stocke le PID et le nom du processus, et toutes les autres métadonnées que vous pourriez vouloir. Plus important, chaque processus a besoin d'avoir sa propre pile, et son pointeur de pile. Ce sont les clés pour sauvegarder et restaurer l'état d'un processus. Sauver l'état est aussi simple que de sauvegarder les registres sur la pile (push), restaurer l'état consiste juste à dépiler les registres (pop). Voici la définition du PCB :
typedef struct {
uint32_t r0;
uint32_t r1;
uint32_t r2;
uint32_t r3;
uint32_t r4;
uint32_t r5;
uint32_t r6;
uint32_t r7;
uint32_t r8;
uint32_t r9;
uint32_t r10;
uint32_t r11;
uint32_t cpsr;
uint32_t sp;
uint32_t lr;
} proc_saved_state_t;
typedef struct pcb {
proc_saved_state_t * saved_state; // Pointeur où est sauvegardé l'état de ce processus sur la pile. Devient invalide une fois que le processus est en cours d'exécution
void * stack_page; // La pile pour ce processus. La pile commence Ă la fin de cette page
uint32_t pid; // Le numéro d'identification du processus
DEFINE_LINK(pcb);
char proc_name[20]; // Le nom du processus
} process_control_block_t;Vous pouvez voir ici que le PCB stocke sa page de pile et un pointeur où l'état de sauvegarde se trouve dans la page. La structure proc_saved_state_t struct représente la façon dont le processus va être sauvegardé dans sa pile. r0 en haut, et lr en bas.
Maintenant que nous avons défini le PCB, nous devons configurer celui du processus en cours.
8-2. Initialiser le processus système▲
De façon à initialiser ce système, nous devons effectuer les choses suivantes :
- Initialiser la liste des processus qui souhaitent être exécutés. Elle s'appelle la Run Queue ;
- Allouer et initialiser un PCB pour le processus principal ;
- Marquer ce processus en processus courant ;
- DĂ©marrer le scheduler (planificateur).
Voici le code pour faire cela :
process_control_block_t * current_process;
...
void process_init(void) {
process_control_block_t * main_pcb;
INITIALIZE_LIST(run_queue);
INITIALIZE_LIST(all_proc_list);
// Alloue et initialise le bloc
main_pcb = kmalloc(sizeof(process_control_block_t));
main_pcb->stack_page = (void *)&__end;
main_pcb->pid = NEW_PID;
memcpy(main_pcb->proc_name, "Init", 5);
// s'ajoute lui-même à la liste de tous les processus. Il est déjà en fonction, donc pas d'ajout à run queue
append_pcb_list(&all_proc_list, main_pcb);
current_process = main_pcb;
// RĂ©gler le timer sur 10 ms
timer_set(10000);
}Ce code crée un nouveau PCB pour le processus principal. Le processus principal a pour nom « init », je me référerai donc à lui en tant que tel à partir de maintenant. Ce PCB contient les informations du processus en cours d'exécution.
La dernière chose que fait ce code est de configurer le timer pour se déclencher après 10 ms. Dans la partie précédenteLes interruptions , nous avons fixé le timer system pour un simple affichage toutes les trois secondes. Nous allons maintenant l'utiliser pour quelque chose de plus important. Le réglage du timer à cet endroit déclenche le système.
8-3. Planification des processus▲
Comme les processus normaux ne perçoivent pas qu'ils ont à partager le CPU, ils n'ont pas de raison de s'arrêter tant qu'ils n'ont pas fini leur travail. Le plus souvent, c'est à nous de stopper le processus pour libérer le CPU. Nous pouvons le faire en utilisant le timer du système. Nous choisissons un intervalle de temps spécifique pendant lequel un processus peut utiliser le CPU. Une fois cet intervalle écoulé, le timer déclenchera une exception et à partir de là nous pourrons commuter sur un autre processus. Comme vous pouvez le voir ci-dessus, l'intervalle que j'ai choisi était de 10 ms.
Il existe plusieurs façons de planifier les processus pour des performances optimales. Pour l'instant, nous allons simplement utiliser la planification « round-robin » ou « FIFO », car elle est incroyablement simple. Tout ce que nous allons faire est d'ajouter le processus en cours à la fin de la file d'attente d'exécution et faire en sorte que le processus en tête de celle-ci soit le nouveau thread en cours. Voici le code :
void schedule(void) {
DISABLE_INTERRUPTS();
process_control_block_t * new_thread, * old_thread;
// s'il n'y a rien dans la run queue, le processus courant doit juste continuer
if (size_pcb_list(&run_queue) == 0)
return;
// Obtient le dernier fil Ă lancer, en utilisant pour l'instant round-robin
new_thread = pop_pcb_list(&run_queue);
old_thread = current_process;
current_process = new_thread;
// Replace le fil courant dans la run queue
append_pcb_list(&run_queue, old_thread);
// Commutation de contexte
switch_to_thread(old_thread, new_thread);
ENABLE_INTERRUPTS();
}Comme vous pouvez le voir, la planification est assez simple. Cette fonction est appelée par timer_irq_handler après 10 ms.
La véritable clé de la planification est dans le commutateur de contexte, l'action qui permute le processus en cours. C'est ce que switch_to_thread fait.
8-4. Commutation de contexte▲
Un changement de contexte implique d'enregistrer tous les registres d'un processus sur sa pile dans un ordre particulier, de sauvegarder ce pointeur de pile sur le PCB, puis de charger le pointeur de pile sauvegardé d'un autre PCB et restaurer les registres de la tâche. Voici le code :
switch_to_thread:
push {lr}
push {sp}
mrs r12, cpsr
push {r0-r12}
str sp, [r0]
ldr sp, [r1]
ldr r0, =#(10000)
bl timer_set
pop {r0-r12}
msr cpsr_c, r12
pop {lr, pc}Cela sauvegarde lr, puis sp sur la pile. Il n'est pas vraiment nécessaire de sauvegarder sp , mais c'est un bon emplacement réutilisable. Ensuite, nous obtenons le registre d'état actuel du programme et l'enregistrons dans r12. r12 est un registre d'enregistrement d'appel, sa valeur n'a donc pas besoin d'être conservée. Ensuite, nous sauvegardons les registres à usage général. Les deux instructions suivantes indiquent où la « commutation » réelle se produit.
Puisque nous sommes passés dans deux PCB, dont le premier champ est le pointeur de pile sauvegardé, nous pouvons accéder à leur pointeur de pile simplement en lisant et en stockant les adresses de mémoire dans r0 et r1. r0 est le pointeur vers l'ancien thread, de sorte que le pointeur de pile actuel avec tout l'état de sauvegarde est mis dans l'état sauvegardé de l'ancien PCB. r1 est le pointeur sur le nouveau thread, de sorte que l'état sauvegardé du nouveau PCB est stocké dans le pointeur de la pile.
Avant de restaurer complètement le nouveau thread, nous réinitialisons le timer afin qu'il se déclenche à nouveau pour un autre intervalle. Ensuite, nous dépilons tous les registres à usage général et restaurons le registre d'état du programme en cours.
La dernière chose que nous devons faire est de reprendre l'exécution du nouveau processus. Nous faisons cela en chargeant le registre enregistré lr dans le registre pc, l'exécution reprendra. Il peut sembler bizarre que ce code stocke le registre enregistré sp dans lr. Puisque lr est sauvegardé par l'appelant, un processus existant remplacera tout ce que nous avons mis dedans lors du retour de l'exception. Un nouveau processus, cependant, saute directement dans le code sans revenir depuis une exception, car techniquement, le nouveau processus n'a jamais eu d'exception. Le nouveau processus ne doit retourner nulle part, donc quand il finira, il utilisera ce lr pour retourner. Nous pouvons en profiter pour qu'un processus saute automatiquement au code de nettoyage quand il meurt.
8-5. CrĂ©er un nouveau processus▲
La création d'un processus implique l'allocation d'espace pour le PCB et la pile de processus, la configuration de la pile de processus sur laquelle le contexte doit être basculé et son ajout à la file d'attente d'exécution (run queue). Voici le code :
void create_kernel_thread(kthread_function_f thread_func, char * name, int name_len) {
process_control_block_t * pcb;
proc_saved_state_t * new_proc_state;
// Allocation et initialisation du PCB
pcb = kmalloc(sizeof(process_control_block_t));
pcb->stack_page = alloc_page();
pcb->pid = NEW_PID;
memcpy(pcb->proc_name, name, MIN(name_len,19));
pcb->proc_name[MIN(name_len,19)+1] = 0;
// Récupère l'emplacement du pointeur de pile attendu lorsque ceci est exécuté
new_proc_state = pcb->stack_page + PAGE_SIZE - sizeof(proc_saved_state_t);
pcb->saved_state = new_proc_state;
// Configure la pile qui sera restaurée pendant un changement de contexte
bzero(new_proc_state, sizeof(proc_saved_state_t));
new_proc_state->lr = (uint32_t)thread_func; // lr est utilisé comme adresse de retour dans switch_to_thread
new_proc_state->sp = (uint32_t)reap; // Lorsque la fonction de thread revient, cette routine la nettoie
new_proc_state->cpsr = 0x13 | (8 << 1); // fixe le thread pour fonctionner en mode superviseur avec irqs seulement
// Ajoute le thread aux listes
append_pcb_list(&all_proc_list, pcb);
append_pcb_list(&run_queue, pcb);
}La partie délicate du code se trouve dans ces lignes :
new_proc_state = pcb->stack_page + PAGE_SIZE - sizeof(proc_saved_state_t);
pcb->saved_state = new_proc_state;
...
new_proc_state->lr = (uint32_t)thread_func;
new_proc_state->sp = (uint32_t)reap; // Quand la fonction du thread s'achève, cette routine la nettoie
new_proc_state->cpsr = 0x13 | (8 << 1);Tout cela configure la pile du nouveau processus de sorte que switch_to_thread fonctionne avec, même s'il n'a jamais été exécuté auparavant.
Les deux premières lignes définissent essentiellement le pointeur de pile. Souvenez-vous que dans la pile, les adresses vont vers le bas, donc la pile commence en haut de la page : pcb-> stack_page + PAGE_SIZE. En soustrayant sizeof (proc_saved_state_t) « pousse » un état sauvegardé vide sur la pile.
Les lignes suivantes renseignent certaines informations vitales. La première indique où le commutateur de contexte doit effectuer le branchement une fois que tout est restauré. Nous voulons que ce soit l'adresse de la fonction pour ce processus. La deuxième ligne fait que ce processus passe au code de nettoyage quand il se termine. La troisième ligne définit ce que le registre d'état du programme actuel contiendra. Puisque nous traitons des threads du noyau, nous voulons rester en mode superviseur (mode 0x13), et nous voulons que les IRQ soient activées quand ce processus démarre (bit 7 = 0). Nous avons positionné le bit 8 pour désactiver un type d'exception que nous n'utilisons pas.
En théorie, nous pourrions passer des arguments à cette fonction en plaçant des valeurs dans r0 à r3, mais nous n'avons pas besoin de cette fonctionnalité pour l'instant, ce sera pour une autre fois.
Cette fonction de récupération contient du code de nettoyage. Tout ce qu'il fait est de libérer toutes les ressources associées à un processus, puis le contexte change immédiatement :
static void reap(void) {
DISABLE_INTERRUPTS();
process_control_block_t * new_thread, * old_thread;
// Si la run queue est vide, il n'y a rien Ă faire donc simplement boucler
while (size_pcb_list(&run_queue) == 0);
// Récupère le prochain thread à exécuter. Pour l'instant, nous utilisons un algorithme de round-robin (permutation circulaire)
new_thread = pop_pcb_list(&run_queue);
old_thread = current_process;
current_process = new_thread;
// Libère les ressources utilisées par l'ancien processus. Techniquement, nous nous retrouvons ici avec des pointeurs invalides, mais comme les interruptions sont désactivées et que nous n'avons qu'un seulcœur, ça devrait toujours être bon
free_page(old_thread->stack_page);
kfree(old_thread);
// Commutation de contexte
switch_to_thread(old_thread, new_thread);
}8-6. Tester le système▲
Dans kernel.c, ajoutez un appel à process_init. Puis au-dessus de kernel_main, créez la fonction suivante :
void test(void) {
int i = 0;
while (1) {
printf("test %d\n", i++);
udelay(1000000);
}
}Et ajoutez ceci à la fin de kernel_main :
create_kernel_thread(test, "TEST", 4);
while (1) {
printf("main %d\n", i++);
udelay(1000000);
}Une fois que vous avez construit le noyau, cela devrait ressembler à ceci :
|
|

Maintenant que nous avons une vraie concurrence, nous risquons d'avoir des collisions de données. Pour aider à résoudre ce problème, nous allons maintenant parler des verrous.
9. Verrous▲
Puisque notre noyau gère maintenant des processus concurrents, nous allons devoir fournir des fonctionnalités pour empêcher les collisions de données. Il y a plusieurs façons de gérer la synchronisation. Je vais me concentrer sur deux d'entre elles : les spin locks et les mutex.
Si vous voulez télécharger le code et le tester par vous-même, consultez mon dépôt git.
9-1. Les swaps atomiques▲
Les spin locks et les mutex reposent tous les deux sur une « variable de verrouillage », une variable qui vaut 1 lorsque le verrou est libre et 0 lorsqu'il est occupé. La partie la plus importante d'une implémentation de verrou est de s'assurer que vous ne pouvez pas être préempté en essayant de prendre le verrou. Par exemple, si vous avez le code suivant :
if (lock == 1)
lock = 0vous pouvez potentiellement être préempté entre l'instruction if et l'affectation. Nous pouvons éviter cela si nous vérifions si nous avons obtenu le verrou après que nous l'avions pris, au lieu de vérifier si nous pouvons le prendre et le prendre ensuite. Nous pouvons le faire en utilisant un échange atomique. Nous pouvons échanger la variable de verrouillage avec 0 sans être préempté. Si la valeur que nous obtenons du swap est toujours 0, cela signifie que quelqu'un d'autre avait le verrou, et nous ne l'avons pas obtenu. Nous avons échangé 0 pour 0, donc rien ne se passe. Si, par contre, nous échangeons 0 et nous obtenons un 1, cela signifie que le verrou était disponible et nous l'avons pris. Nous avons laissé un 0 à sa place, indiquant que le verrou est pris.
Nous pouvons uniquement accéder à ce swap atomique en assembleur. Voici le code :
.section ".text"
.global try_lock
// Cette fonction prend un pointeur vers une variable de verrouillage et utilise des opérations atomiques pour acquérir le verrou.
// Renvoie 0 si le verrou n'a pas été acquis et 1 s'il l'a été.
try_lock:
mov r1, #0
swp r2, r1, [r0] // stocke la valeur du registre r1 à l'adresse pointée par r0, et stocke la valeur précédemment à cette même adresse dans le registre r2
mov r0, r2
blx lrNous pouvons maintenant utiliser les spin locks et les mutex.
9-2. Spin locks▲
Un spin lock est la méthode de synchronisation la plus élémentaire possible. Il ne permet qu'à un seul processus à la fois de gérer le verrou. L'implémentation est très simple : essayer d'acquérir le verrou dans une boucle jusqu'à ce qu'il soit acquis. C'est cette boucle qui donne son nom au spin lock. Le verrou « tourne » dans cette boucle d'acquisition, le CPU consomme des cycles d'horloge pendant ce temps.
Parce qu'un spin lock consomme les cycles du processeur, c'est une technique peu efficace. Le cas d'utilisation principal est celui d'une ressource qui devient disponible très rapidement. C'est bien pour accéder aux structures de données du noyau qui sont toujours en mémoire, mais c'est très inadapté à la synchronisation relative aux accès réseau ou disque.
Voici le code :
typedef int spin_lock_t;
...
void spin_init(spin_lock_t * lock) {
*lock = 1;
}
void spin_lock(spin_lock_t * lock) {
while (!try_lock(lock));
}
void spin_unlock(spin_lock_t * lock) {
*lock = 1;
}9-3. Les mutex▲
Un mutex est similaire à un spin lock en ce sens qu'il ne peut être possédé que par un seul processus à la fois. Il diffère dans sa mise en œuvre qui est plus compliquée, mais permet au verrou d'être maintenu pendant des périodes prolongées sans consommer de cycles d'horloge du processeur.
Cela se fait en maintenant une file d'attente des processus qui tentent de le verrouiller. Au lieu de boucler, le mutex ajoutera le processus qui veut le verrou à sa file d'attente, puis planifiera un nouveau processus sans l'ajouter à la file d'attente d'exécution. De cette façon, le processus qui veut le verrou ne s'exécutera jamais pendant qu'il attend, et ne consommera donc pas les cycles du processeur. Lorsqu'un processus libère le verrou, il prend un processus dans la file d'attente et le rajoute dans la file d'attente d'exécution afin qu'il puisse revendiquer le verrou.
Voici le code :
typedef struct {
int lock;
process_control_block_t * locker;
pcb_list_t wait_queue;
} mutex_t;
...
void mutex_init(mutex_t * lock) {
lock->lock = 1;
lock->locker = 0;
INITIALIZE_LIST(lock->wait_queue);
}
void mutex_lock(mutex_t * lock) {
process_control_block_t * new_thread, * old_thread;
// Si le verrou n'est pas obtenu, s'extraire de la file d'attente d'exécution et se mettre dans la file d'attente mutex
while (!try_lock(&lock->lock)) {
// Obtient le prochain thread à exécuter. Pour le moment, nous utilisons l'algorithme de round-robin
DISABLE_INTERRUPTS();
new_thread = pop_pcb_list(&run_queue);
old_thread = current_process;
current_process = new_thread;
// Remet le thread courant dans la file d'attente de ce mutex, pas dans la file d'attente d'exécution
append_pcb_list(&lock->wait_queue, old_thread);
// Changement de contexte
switch_to_thread(old_thread, new_thread);
ENABLE_INTERRUPTS();
}
lock->locker = current_process;
}
void mutex_unlock(mutex_t * lock) {
process_control_block_t * thread;
lock->lock = 1;
lock->locker = 0;
// S'il y a un thread en attente du verrou, on le remet dans la file d'attente d'exécution
if (size_pcb_list(&lock->wait_queue)) {
thread = pop_pcb_list(&lock->wait_queue);
push_pcb_list(&run_queue, thread);
}
}9-4. Utiliser les verrous▲
Vous pouvez tester le mutex en déclarant un mutex global dans kernel.c, en l'initialisant dans kernel_main, et en ajoutant le code suivant aux boucles de kernel_main puis tester :
if (i % 10 == 0)
mutex_lock(&test_mut);
else if (i % 10 == 9)
mutex_unlock(&test_mut);Au lieu d'alterner main x et tester x Ă chaque ligne, il faut maintenant alterner toutes les dix lignes.
C'est un bon test, mais pour en avoir pour notre argent, nous pouvons ajouter une synchronisation à l'implémentation de la liste, ainsi toutes les listes du noyau seront à l'abri des collisions de données. Nous devons utiliser un spin lock pour cela, car l'implémentation de la liste est utilisée à l'intérieur de mutex, et nous ne pouvons pas avoir ce type de définition circulaire.
10. Annexes▲
10-1. Une explication dĂ©taillĂ©e de boot.S▲
10-1-1. Rappel de la source de boot.SÂ ▲
.section ".text.boot"
.global _start
_start:
mrc p15, #0, r1, c0, c0, #5
and r1, r1, #3
cmp r1, #0
bne halt
mov sp, #0x8000
ldr r4, =__bss_start
ldr r9, =__bss_end
mov r5, #0
mov r6, #0
mov r7, #0
mov r8, #0
b 2f
1:
stmia r4!, {r5-r8}
2:
cmp r4, r9
blo 1b
ldr r3, =kernel_main
blx r3
halt:
wfe
b haltJetons un Ĺ“il au code source ligne par ligne.
10-1-2. Setting up the C Runtime Environment▲
.section ".text.boot"
.globl _startCe sont des notes pour l'éditeur de liens. La première indique la section dont le code fait partie dans le binaire compilé. Dans un instant, nous allons préciser où cela se trouve. La seconde ligne spécifie que _start est un nom qui doit être visible depuis l'extérieur du fichier assembleur.
_start:
mrc p15, #0, r1, c0, c0, #5
and r1, r1, #3
cmp r1, #0
bne haltCe sont les premières instructions de notre noyau. Ces lignes enverront trois des quatre cœurs vers halt, les arrêtant effectivement. Écrire un système d'exploitation est difficile, écrire un système d'exploitation multicœur est encore plus difficile.
mov sp, #0x8000Cela indique que notre pile C doit commencer à l'adresse 0x8000 et croître vers le bas. Pourquoi 0x8000 ? Eh bien, quand le matériel charge notre noyau dans la mémoire, il ne le charge pas à l'adresse 0, mais à l'adresse 0x8000. Comme notre noyau démarre à partir de 0x8000 et plus, notre pile peut fonctionner en toute sécurité à partir de 0x8000 et vers le bas sans entrer en collision avec notre noyau.
ldr r4, =__bss_start
ldr r9, =__bss_endCela charge les adresses des extrémités de début et de fin de la section BSS dans les registres. BSS est la section où les variables globales C qui ne sont pas initialisées au moment de la compilation sont stockées. L'environnement d'exécution C nécessite que les variables globales non initialisées soient égales à zéro, nous devons donc nous-mêmes mettre cette section à zéro. Les symboles __bss_start et __bss_end vont être définis plus tard lorsque nous travaillerons avec l'éditeur de liens, donc ne vous inquiétez pas de leur provenance pour l'instant.
mov r5, #0
mov r6, #0
mov r7, #0
mov r8, #0
b 2f
1:
stmia r4!, {r5-r8}
2:
cmp r4, r9
blo 1bCe code est celui qui met à zéro la section BSS. D'abord, il charge 0 dans quatre registres consécutifs. Ensuite, il vérifie si l'adresse stockée dans r4 est inférieure à celle présente dans r9. Si c'est le cas, alors il exécute stmia r4 !, {r5-r8}. L'instruction stm stocke le deuxième opérande dans l'adresse contenue dans le premier. Le suffixe ia de l'instruction signifie incrémenter après, ou incrémenter l'adresse dans r4 à l'adresse après la dernière adresse écrite par l'instruction. Le « ! » signifie remettre cette adresse dans r4, au lieu de la jeter. L'opérande {r5-r8} signifie que stm doit stocker les valeurs dans les registres consécutifs r5, r6, r7, r8 (donc 16 octets) dans r4. Donc globalement, l'instruction stocke 16 octets de zéros dans l'adresse r4, puis incrémente cette adresse de 16 octets. Cela boucle jusqu'à ce que r4 soit supérieur ou égal à r9, et toute la section BSS est mise à zéro.
ldr r3, =kernel_main
blx r3
halt:
wfe
b haltCeci charge l'adresse de la fonction C appelée kernel_main dans un registre et saute à cet endroit. Lorsque la fonction C retourne, elle entre dans la procédure d'arrêt où elle boucle pour toujours sans rien faire.
10-2. Une explication dĂ©taillĂ©e de kernel.c▲
10-2-1. Source kernel.c ▲
Rappel du code de kernel.c :
kernel.c
#include <stddef.h>
#include <stdint.h>
static inline void mmio_write(uint32_t reg, uint32_t data)
{
*(volatile uint32_t*)reg = data;
}
static inline uint32_t mmio_read(uint32_t reg)
{
return *(volatile uint32_t*)reg;
}
// Boucle « delay » fois d'une manière non optimisée par le compilateur
static inline void delay(int32_t count)
{
asm volatile("__delay_%=: subs %[count], %[count], #1; bne __delay_%=\n"
: "=r"(count): [count]"0"(count) : "cc");
}
enum
{
// Adresses de base des registres du GPIO.
GPIO_BASE = 0x3F200000, // pour raspi2 et 3, 0x20200000 pour raspi1
GPPUD = (GPIO_BASE + 0x94),
GPPUDCLK0 = (GPIO_BASE + 0x98),
// Adresses de base pour l'UART.
UART0_BASE = 0x3F201000, // pour raspi2 et 3, 0x20201000 pour raspi1
UART0_DR = (UART0_BASE + 0x00),
UART0_RSRECR = (UART0_BASE + 0x04),
UART0_FR = (UART0_BASE + 0x18),
UART0_ILPR = (UART0_BASE + 0x20),
UART0_IBRD = (UART0_BASE + 0x24),
UART0_FBRD = (UART0_BASE + 0x28),
UART0_LCRH = (UART0_BASE + 0x2C),
UART0_CR = (UART0_BASE + 0x30),
UART0_IFLS = (UART0_BASE + 0x34),
UART0_IMSC = (UART0_BASE + 0x38),
UART0_RIS = (UART0_BASE + 0x3C),
UART0_MIS = (UART0_BASE + 0x40),
UART0_ICR = (UART0_BASE + 0x44),
UART0_DMACR = (UART0_BASE + 0x48),
UART0_ITCR = (UART0_BASE + 0x80),
UART0_ITIP = (UART0_BASE + 0x84),
UART0_ITOP = (UART0_BASE + 0x88),
UART0_TDR = (UART0_BASE + 0x8C),
};
void uart_init()
{
mmio_write(UART0_CR, 0x00000000);
mmio_write(GPPUD, 0x00000000);
delay(150);
mmio_write(GPPUDCLK0, (1 << 14) | (1 << 15));
delay(150);
mmio_write(GPPUDCLK0, 0x00000000);
mmio_write(UART0_ICR, 0x7FF);
mmio_write(UART0_IBRD, 1);
mmio_write(UART0_FBRD, 40);
mmio_write(UART0_LCRH, (1 << 4) | (1 << 5) | (1 << 6));
mmio_write(UART0_IMSC, (1 << 1) | (1 << 4) | (1 << 5) | (1 << 6) |
(1 << 7) | (1 << 8) | (1 << 9) | (1 << 10));
mmio_write(UART0_CR, (1 << 0) | (1 << 8) | (1 << 9));
}
void uart_putc(unsigned char c)
{
while ( mmio_read(UART0_FR) & (1 << 5) ) { }
mmio_write(UART0_DR, c);
}
unsigned char uart_getc()
{
while ( mmio_read(UART0_FR) & (1 << 4) ) { }
return mmio_read(UART0_DR);
}
void uart_puts(const char* str)
{
for (size_t i = 0; str[i] != '\0'; i ++)
uart_putc((unsigned char)str[i]);
}
void kernel_main(uint32_t r0, uint32_t r1, uint32_t atags)
{
(void) r0;
(void) r1;
(void) atags;
uart_init();
uart_puts("Hello, kernel World!\r\n");
while (1) {
uart_putc(uart_getc());
uart_putc('\n');
}
}10-2-2. SpĂ©cification pĂ©riphĂ©rique et lecture Ă©criture de base▲
Si vous n'êtes pas familier avec les entrées/sorties mappées en mémoire sur le Raspberry Pi, je vous recommande de lire les entrées/sorties mappées en mémoire, les périphériques et les registresLes entrées/sorties mappées en mémoire, les périphériques et les registres avant de continuer.
static inline void mmio_write(uint32_t reg, uint32_t data)
{
*(volatile uint32_t*)reg = data;
}
static inline uint32_t mmio_read(uint32_t reg)
{
return *(volatile uint32_t*)reg;
}
static inline void delay(int32_t count)
{
asm volatile("__delay_%=: subs %[count], %[count], #1; bne __delay_%=\n"
: "=r"(count): [count]"0"(count) : "cc");
}
enum
{
// Adresses de base des registres du GPIO.
GPIO_BASE = 0x3F200000, // for raspi2 & 3, 0x20200000 for raspi1
GPPUD = (GPIO_BASE + 0x94),
GPPUDCLK0 = (GPIO_BASE + 0x98),
// Adresses de base pour l'UART.
UART0_BASE = 0x3F201000, // for raspi2 & 3, 0x20201000 for raspi1
UART0_DR = (UART0_BASE + 0x00),
UART0_RSRECR = (UART0_BASE + 0x04),
UART0_FR = (UART0_BASE + 0x18),
UART0_ILPR = (UART0_BASE + 0x20),
UART0_IBRD = (UART0_BASE + 0x24),
UART0_FBRD = (UART0_BASE + 0x28),
UART0_LCRH = (UART0_BASE + 0x2C),
UART0_CR = (UART0_BASE + 0x30),
UART0_IFLS = (UART0_BASE + 0x34),
UART0_IMSC = (UART0_BASE + 0x38),
UART0_RIS = (UART0_BASE + 0x3C),
UART0_MIS = (UART0_BASE + 0x40),
UART0_ICR = (UART0_BASE + 0x44),
UART0_DMACR = (UART0_BASE + 0x48),
UART0_ITCR = (UART0_BASE + 0x80),
UART0_ITIP = (UART0_BASE + 0x84),
UART0_ITOP = (UART0_BASE + 0x88),
UART0_TDR = (UART0_BASE + 0x8C),
};mmio_write et mmio_read prennent tous les deux en entrée un registre qui est une adresse absolue correspondant à 0x20000000 + adresse de base du périphérique + décalage de registre. write prend un mot de 4 octets pour écrire dans le registre, tandis que read renvoie n'importe quel mot de 4 octets dans le registre. delay est juste une fonction qui occupe les boucles pendant un moment. C'est une manière très imprécise de donner au matériel le temps de répondre aux écritures que nous aurions pu faire.
L'énumération définit le décalage périphérique du GPIO et des systèmes matériels UART, ainsi que certains de leurs registres. Ne vous inquiétez pas de savoir à quoi correspond chaque registre, car je vais l'expliquer au fur et à mesure de leur utilisation.
10-2-3. Configurer le matĂ©riel▲
void uart_init()
{
mmio_write(UART0_CR, 0x00000000);
mmio_write(GPPUD, 0x00000000);
delay(150);
mmio_write(GPPUDCLK0, (1 << 14) | (1 << 15));
delay(150);
mmio_write(GPPUDCLK0, 0x00000000);
mmio_write(UART0_ICR, 0x7FF);
mmio_write(UART0_IBRD, 1);
mmio_write(UART0_FBRD, 40);
mmio_write(UART0_LCRH, (1 << 4) | (1 << 5) | (1 << 6));
mmio_write(UART0_IMSC, (1 << 1) | (1 << 4) | (1 << 5) | (1 << 6) |
(1 << 7) | (1 << 8) | (1 << 9) | (1 << 10));
mmio_write(UART0_CR, (1 << 0) | (1 << 8) | (1 << 9));
}Il s'agit de la fonction uart_init. Elle configure le matériel UART à utiliser. Elle consiste simplement à définir des drapeaux de configuration dans divers registres.
mmio_write(UART0_CR, 0x00000000);Cette ligne désactive tous les aspects du matériel UART. UART0_CR est le registre de contrôle de l'UART.
mmio_write(GPPUD, 0x00000000);
delay(150);
mmio_write(GPPUDCLK0, (1 << 14) | (1 << 15));
delay(150);
mmio_write(GPPUDCLK0, 0x00000000);Ces lignes désactivent les broches 14 et 15 du GPIO. Écrire 0 à GPPUD indique que les broches doivent être désactivées. Écrire (1 << 14) | (1 << 15) dans GPPUDCLK0 indique quelles broches doivent être désactivées, et l'écriture de 0 dans GPPUDCLK0 rend l'ensemble effectif. Puisque nous n'utilisons pas les broches GPIO, cette partie n'est pas vraiment importante.
mmio_write(UART0_ICR, 0x7FF);Cette ligne définit tous les drapeaux dans le Interrupt Clear Register (registre d'effacement d'interruption). Cela a pour effet de supprimer toutes les interruptions en attente du matériel UART. Ce que sont les interruptions et leur fonctionnement sera abordé dans leur propre section, je ne vais donc pas en parler ici.
mmio_write(UART0_IBRD, 1);
mmio_write(UART0_FBRD, 40);Ceci définit le débit en bauds de la connexion (baud rate). C'est essentiellement le nombre de bits par seconde qui peut transiter par le port série. Ce code essaie d'obtenir un débit de 115 200 bauds. Pour définir ce débit, nous devons calculer un diviseur en bauds et le placer dans certains registres. Le diviseur est calculé par UART_CLOCK_SPEED / (16 * DESIRED_BAUD). La partie entière de ce calcul va dans IBRD, le registre de l'UART. Ce calcul ne donne probablement pas un nombre entier, et dans notre cas, il se situe à environ 1,67. Cela signifie que nous stockons 1 dans la IRBD et que nous devons également calculer un diviseur fractionnaire du débit en bauds à partir de la partie fractionnaire du calcul précédent en utilisant cette formule (0.67 * 64) + 0,5. Cela donne environ 40, donc nous avons mis le registre FBRD à 40.
mmio_write(UART0_LCRH, (1 << 4) | (1 << 5) | (1 << 6));Ceci écrit les bits 4, 5 et 6 dans le registre de contrôle de ligne (Line control register). Le réglage du bit 4 signifie que le matériel UART conservera les données dans un FIFO d'une profondeur de 8 éléments, au lieu d'un registre d'une profondeur d'un élément. Le réglage des bits 5 et 6 à 1 signifie que les données envoyées ou reçues seront des mots de 8 bits.
mmio_write(UART0_IMSC, (1 << 1) | (1 << 4) | (1 << 5) | (1 << 6) |
(1 << 7) | (1 << 8) | (1 << 9) | (1 << 10));Ceci permet de désactiver toutes les interruptions de l'UART en écrivant un 1 dans les bits pertinents du registre Interrupt Mask Set Clear register.
mmio_write(UART0_CR, (1 << 0) | (1 << 8) | (1 << 9));Ceci écrit les bits 0, 8 et 9 dans le registre de contrôle. Le bit 0 active le matériel UART, le bit 8 permet la réception de données et le bit 9 leur transmission.
10-2-4. Lire et Ă©crire du texte▲
void uart_putc(unsigned char c)
{
while ( mmio_read(UART0_FR) & (1 << 5) ) { }
mmio_write(UART0_DR, c);
}
unsigned char uart_getc()
{
while ( mmio_read(UART0_FR) & (1 << 4) ) { }
return mmio_read(UART0_DR);
}
void uart_puts(const char* str)
{
for (size_t i = 0; str[i] != '\0'; i ++)
uart_putc((unsigned char)str[i]);
}Ce code permet de lire et d'écrire des caractères depuis et vers l'UART. FR est le registre des drapeaux (Flag Register). Il indique si le FIFO de lecture contient des données à lire et si le FIFO d'écriture peut accepter des données. DR est le registre de données (Data Register), où les données sont lues et écrites. La fonction uart_puts encapsule simplement putc dans une boucle pour que nous puissions écrire des chaînes entières.
10-2-5. Le cĹ“ur du noyau▲
void kernel_main(uint32_t r0, uint32_t r1, uint32_t atags)
{
// Declarés comme inutilisés
(void) r0;
(void) r1;
(void) atags;
uart_init();
uart_puts("Hello, kernel World!\r\n");
while (1) {
uart_putc(uart_getc());
uart_putc('\n');
}
}C'est la fonction principale de notre noyau. C'est là que le contrôle est transféré depuis boot.S. Tout ce que fait cette fonction, c'est appeler la fonction init_uart, afficher « Hello, kernel World! », et afficher les caractères que vous tapez. C'est là que nous allons ajouter des appels à de nombreuses autres fonctions d'initialisation.
Les arguments de cette fonction semblent un peu étranges. Normalement, la fonction main du code C ressemble à quelque chose comme int main (int argc, char ** argv), mais notre kernel_main n'a rien à voir avec ça. En ARM, la convention est que les trois premiers paramètres d'une fonction passent par les registres r0, r1 et r2. Lorsque le bootloader charge notre noyau, il place également des informations sur le matériel et la ligne de commande utilisée pour exécuter le noyau en mémoire. Ces informations sont appelées atags, et un pointeur sur atags est placé dans r2 juste avant l'exécution de boot.S. Donc, pour notre kernel_main, r0 et r1 sont simplement des paramètres de la fonction par convention, mais nous ne nous en soucions pas. r2 contient le pointeur atags, donc le troisième argument de kernel_main est le pointeur atags.
10-3. Les entrĂ©es/sorties mappĂ©es en mĂ©moire, les pĂ©riphĂ©riques et les registres▲
- Memory Mapped IO ou MMIO (Entrées/sorties mappées en mémoire) est le processus d'interaction avec les périphériques matériels effectué en lisant et en écrivant à des adresses mémoire prédéfinies. Toutes les interactions avec le matériel sur le Raspberry Pi s'effectuent en utilisant MMIO.
- Un Péripherique est un dispositif matériel disposant d'une adresse spécifique dans la mémoire à laquelle il écrit et/ou lit des données. Tous les périphériques peuvent être décrits par un décalage par rapport à la Peripheral Base Address (l'adresse de base du périphérique), qui commence à 0x20000000 sur le modèle Raspberry Pi 1, et à 0x0x3F000000 sur les modèles 2 et 3.
- Un Registre est une zone de mémoire de quatre octets où un périphérique peut lire ou écrire. Ces registres sont à des décalages prédéfinis à partir de l'adresse de base du périphérique. Par exemple, il est assez courant qu'au moins un registre soit un registre de contrôle, où chaque bit correspond à un comportement que le matériel doit avoir. Un autre type de registre courant est un registre d'écriture, où tout ce qui est écrit est transmis au matériel.
Déterminer où se trouvent tous les périphériques, de quels registres ils disposent et comment les utiliser est décrit principalement dans le manuel du périphérique BCM2835 ARM. Le BCM2835 est le nom du chipset utilisé par le Raspberry Pi modèle 1, et la plupart des informations sont aussi valides pour les modèles 2 et 3. Ce document n'est pas facile à appréhender et il manque beaucoup d'informations, mais c'est un bon point de départ, ainsi que la preuve que je n'invente pas toutes ces adresses.
10-4. Une explication dĂ©taillĂ©e de linker.ld▲
10-4-1. Source linker.ld ▲
Rappel du code source de linker.ld :
ENTRY(_start)
SECTIONS
{
/* DĂ©marre Ă LOADER_ADDR. */
. = 0x8000;
__start = .;
__text_start = .;
.text :
{
KEEP(*(.text.boot))
*(.text)
}
. = ALIGN(4096); /* alignement Ă la taille de page */
__text_end = .;
__rodata_start = .;
.rodata :
{
*(.rodata)
}
. = ALIGN(4096); /* alignement Ă la taille de page */
__rodata_end = .;
__data_start = .;
.data :
{
*(.data)
}
. = ALIGN(4096); /* alignement Ă la taille de page */
__data_end = .;
__bss_start = .;
.bss :
{
bss = .;
*(.bss)
}
. = ALIGN(4096); /* alignement Ă la taille de page */
__bss_end = .;
__end = .;
}Jetons un Ĺ“il sur le code ligne par ligne.
10-4-2. Quelques notes Ă propos de l'Ă©dition de liens▲
- Dans un script d'édition de liens, . signifie adresse courante. Vous pouvez définir l'adresse courante et également affecter des choses pointées par l'adresse courante.
-
Revue des sections d'un programme CÂ :
- .text là où se trouve le code exécutable ;
- .rodata données en lecture seule, c'est là que se trouvent les constantes globales ;
- .data emplacement où se trouvent les variables globales qui sont initialisées au moment de la compilation ;
- .bss emplacement des variables globales non initialisées.
10-4-3. Mettre les sections au bon endroit▲
ENTRY(_start)Ceci déclare que le symbole _start de boot.S est le point d'entrée de notre code.
. = 0x8000;
__start = .;
__text_start = .;
.text :
{
KEEP(*(.text.boot))
*(.text)
}
. = ALIGN(4096); /* alignement Ă la taille de page */
__text_end = .;Ceci affecte l'adresse 0x8000 aux symboles __start et __text_start. Le code déclare ensuite que la section .text commence juste après. La première partie de la section .text est .text.boot, là où réside le code de boot.S. KEEP signifie que l'éditeur de liens ne doit pas essayer d'optimiser le code dans .text.boot même s'il n'est référencé nulle part. La deuxième partie de la section .text contient toutes les sections .text de tous les autres objets, dans n'importe quel ordre. Ensuite, elle déclare __text_end comme étant la plus grande adresse, divisible par 4096 après la mise en place des sections .text. Cet arrondi au multiple de 4096 le plus proche est appelé alignement de page et il devient important lorsque nous commençons à utiliser la mémoire.
__rodata_start = .;
.rodata :
{
*(.rodata)
}
. = ALIGN(4096); /* alignement Ă la taille de page */
__rodata_end = .;
__data_start = .;
.data :
{
*(.data)
}
. = ALIGN(4096); /* alignement Ă la taille de page */
__data_end = .;
__bss_start = .;
.bss :
{
bss = .;
*(.bss)
}
. = ALIGN(4096); /* alignement Ă la taille de page */
__bss_end = .;
__end = .;De même, nous déclarons que __rodata_start est identique à __text_end, puis nous déclarons la section .rodata qui comprend toutes les sections .rodata de tous les fichiers objets, puis déclarons que __rodata_end est l'adresse de la page suivante après le .rodata. Nous répétons ensuite ceci pour les sections .data et .bss.
10-5. Une explication dĂ©taillĂ©e sur le makefile▲
10-5-1. Source du Makefile▲
Rappel du code source du Makefile :
# Ne pas utiliser le gcc standard mais le compilateur croisé arm
CC = ./gcc-arm-none-eabi-6-2017-q2-update/bin/arm-none-eabi-gcc
# Affecte des constantes basées sur le modèle de raspberry. La version 1 a quelques différences avec les versions 2 et 3
ifeq ($(RASPI_MODEL),1)
CPU = arm1176jzf-s
DIRECTIVES = -D MODEL_1
else
CPU = cortex-a7
endif
CFLAGS= -mcpu=$(CPU) -fpic -ffreestanding $(DIRECTIVES)
CSRCFLAGS= -O2 -Wall -Wextra
LFLAGS= -ffreestanding -O2 -nostdlib
# Emplacement des fichiers
KER_SRC = ../src/kernel
KER_HEAD = ../include
COMMON_SRC = ../src/common
OBJ_DIR = objects
KERSOURCES = $(wildcard $(KER_SRC)/*.c)
COMMONSOURCES = $(wildcard $(COMMON_SRC)/*.c)
ASMSOURCES = $(wildcard $(KER_SRC)/*.S)
OBJECTS = $(patsubst $(KER_SRC)/%.c, $(OBJ_DIR)/%.o, $(KERSOURCES))
OBJECTS += $(patsubst $(COMMON_SRC)/%.c, $(OBJ_DIR)/%.o, $(COMMONSOURCES))
OBJECTS += $(patsubst $(KER_SRC)/%.S, $(OBJ_DIR)/%.o, $(ASMSOURCES))
HEADERS = $(wildcard $(KER_HEAD)/*.h)
IMG_NAME=kernel.img
build: $(OBJECTS) $(HEADERS)
echo $(OBJECTS)
$(CC) -T linker.ld -o $(IMG_NAME) $(LFLAGS) $(OBJECTS)
$(OBJ_DIR)/%.o: $(KER_SRC)/%.c
mkdir -p $(@D)
$(CC) $(CFLAGS) -I$(KER_SRC) -I$(KER_HEAD) -c $< -o $@ $(CSRCFLAGS)
$(OBJ_DIR)/%.o: $(KER_SRC)/%.S
mkdir -p $(@D)
$(CC) $(CFLAGS) -I$(KER_SRC) -c $< -o $@
$(OBJ_DIR)/%.o: $(COMMON_SRC)/%.c
mkdir -p $(@D)
$(CC) $(CFLAGS) -I$(KER_SRC) -I$(KER_HEAD) -c $< -o $@ $(CSRCFLAGS)
clean:
rm -rf $(OBJ_DIR)
rm $(IMG_NAME)
run: build
qemu-system-arm -m 256 -M raspi2 -serial stdio -kernel kernel.imgJetons un Ĺ“il ligne par ligne.
10-5-2. RĂ©gler les variables▲
CC = ./gcc-arm-none-eabi-6-2017-q2-update/bin/arm-none-eabi-gccCela définit le compilateur que nous allons utiliser comme compilateur croisé, celui que nous avons téléchargé lors de la configuration de notre environnement de développementConstruire l'environnement de développement.
ifeq ($(RASPI_MODEL),1)
CPU = arm1176jzf-s
DIRECTIVES = -D MODEL_1
else
CPU = cortex-a7
endifIl existe des différences de matériel entre les modèles de Raspberry Pi. Comme je suis en train de développer pour une VM modèle 2 et un vrai modèle 1, j'utilise les options par défaut du modèle 2, et je dois activer les options du modèle 1 manuellement. Je le fais en passant RASPI_MODEL=1 comme paramètre à make. En plus de définir le processeur approprié, il ajoute également la directive préprocesseur MODEL_1. Tout code C qui dépend de matériels différents, comme l'adresse de base de périphériqueLes entrées/sorties mappées en mémoire, les périphériques et les registres, peut déterminer pour quel matériel compiler en fonction de l'utilisation de la directive de préprocesseur #ifdef MODEL_1.
CFLAGS= -mcpu=$(CPU) -fpic -ffreestanding $(DIRECTIVES)
CSRCFLAGS= -O2 -Wall -Wextra
LFLAGS= -ffreestanding -O2 -nostdlibCe sont exactement les mêmes options de compilation et d'édition de liens que nous avons utilisés auparavantlinker.ld - Attacher les morceaux ensemble, mais définis comme variables.
KER_SRC = ../src/kernel
KER_HEAD = ../include
COMMON_SRC = ../src/commonCes lignes spécifient les répertoires où se trouvent respectivement les fichiers source du noyau, les fichiers d'en-tête et les fichiers source communs. Ils commencent par ../ car le Makefile sera exécuté en dehors du dossier build.
OBJ_DIR = objectsDe même, cette ligne spécifie l'emplacement d'un répertoire où stocker tous les fichiers objets binaires. Ce répertoire n'existe peut-être pas et vous ne devrez pas le créer. Il sera créé par le fichier make quand il le faudra.
KERSOURCES = $(wildcard $(KER_SRC)/*.c)
COMMONSOURCES = $(wildcard $(COMMON_SRC)/*.c)
ASMSOURCES = $(wildcard $(KER_SRC)/*.S)
...
HEADERS = $(wildcard $(KER_HEAD)/*.h)Cela récupère respectivement une liste de tous les fichiers source du noyau, les fichiers source communs, les fichiers source assembleur, et les fichiers d'en-tête. wildcard est une commande de make qui énumère tous les fichiers correspondant au motif donné. Donc $(wildcard $(KER_SRC)/*. C) retourne la liste de tous les fichiers du répertoire KER_SRC qui ont comme suffixe .c.
OBJECTS = $(patsubst $(KER_SRC)/%.c, $(OBJ_DIR)/%.o, $(KERSOURCES))
OBJECTS += $(patsubst $(COMMON_SRC)/%.c, $(OBJ_DIR)/%.o, $(COMMONSOURCES))
OBJECTS += $(patsubst $(KER_SRC)/%.S, $(OBJ_DIR)/%.o, $(ASMSOURCES))Cela prend les listes des fichiers source du noyau, des fichiers source communs et des fichiers source assembleur, et les ajoute tous à une liste de fichiers objet compilés qui seront créés. C'est fait en utilisant patsubst qui remplace par le deuxième argument toutes les occurrences du motif spécifié en premier argument trouvées dans le dernier argument. Le % présent dans le deuxième argument est remplacé par le texte qui correspond à % dans le troisième argument. Par exemple, $(patsubst $(KER_SRC)/%.c, $(OBJ_DIR)/%.o, $(KERSOURCES)) convertit tous les noms de fichiers de type ../src/kernel/file.c en objects/file.o.
IMG_NAME=kernel.imgCette variable est le nom du binaire noyau.
10-5-3. La cible make▲
Les makefiles fonctionnent à travers une série de cibles. Chaque cible a une liste de dépendances et une liste de commandes à exécuter. Si des dépendances n'existent pas ou sont plus récentes que la cible, les commandes associées sont exécutées. Une cible est exécutée en lançant make suivi du nom de la cible. Notre fichier makefile a les cibles suivantes :
build: $(OBJECTS) $(HEADERS)
echo $(OBJECTS)
$(CC) -T linker.ld -o $(IMG_NAME) $(LFLAGS) $(OBJECTS)C'est la cible principale, celle qui compile le noyau. Elle peut être appelée en exécutant make build. Elle dépend de tous les fichiers objet des fichiers de code source respectifs et de tous les fichiers d'en-tête. Cela signifie que tous les fichiers objets doivent être compilés avant qu'elle puisse s'exécuter. Sa seule fonction consiste à lier tous les objets dans le binaire final du noyau.
$(OBJ_DIR)/%.o: $(KER_SRC)/%.c
mkdir -p $(@D)
$(CC) $(CFLAGS) -I$(KER_SRC) -I$(KER_HEAD) -c $< -o $@ $(CSRCFLAGS)Cette cible représente tout fichier objet qui dépend d'un fichier source du noyau. Elle crée le répertoire objects s'il n'existe pas, puis compile le fichier source dans le fichier objet. -I permet aux fichiers source d'accéder aux fichiers include par #include <kernel/header.h> au lieu de #include<../../include/kernel/header/h>. $< est le nom de la première dépendance, donc le fichier source c. $@ est le nom du fichier cible lui-même.
Il y a deux autres cibles très similaires. L'une concerne les fichiers assembleur du noyau à la place des fichiers source du noyau et l'autre concerne les fichiers source communs.
clean:
rm -rf $(OBJ_DIR)
rm $(IMG_NAME)Cette cible supprime tous les fichiers binaires compilés afin qu'aucun fichier périmé ne soit accidentellement utilisé lors de l'exécution du make.
run: build
qemu-system-arm -m 256 -M raspi2 -serial stdio -kernel kernel.imgCela garantit que le noyau est compilé, puis exécute la machine virtuelle avec ce noyau compilé.
Cela réduit la construction et le processus de test à  :
make build
make run10-6. Une explication dĂ©taillĂ©e sur list.h▲
Pour de nombreuses opérations du noyau, il est nécessaire d'avoir une structure de données de liste chaînée pour pouvoir garder une trace de tout. Voici une implémentation de liste liée qui réimplémente la liste pour chaque nouveau type pour lequel vous avez besoin d'une liste liée.
10-6-1. Source list.h▲
Voici la source de list.h :
#ifndef LIST_H
#define LIST_H
#define DEFINE_LIST(nodeType) \
typedef struct nodeType##list { \
struct nodeType * head; \
struct nodeType * tail; \
uint32_t size;\
} nodeType##_list_t;
#define DEFINE_LINK(nodeType) \
struct nodeType * next##nodeType;\
struct nodeType * prev##nodeType;
#define INITIALIZE_LIST(list) \
list.head = list.tail = (void *)0;\
list.size = 0;
#define IMPLEMENT_LIST(nodeType) \
void append_##nodeType##_list(nodeType##_list_t * list, struct nodeType * node) { \
list->tail->next##nodeType = node; \
node->prev##nodeType = list->tail; \
list->tail = node; \
node->next##nodeType = NULL; \
list->size += 1; \
} \
\
void push_##nodeType##_list(nodeType##_list_t * list, struct nodeType * node) { \
node->next##nodeType = list->head; \
node->prev##nodeType = NULL; \
list->head = node; \
list->size += 1; \
} \
\
struct nodeType * peek_##nodeType##_list(nodeType##_list_t * list) { \
return list->head; \
} \
\
struct nodeType * pop_##nodeType##_list(nodeType##_list_t * list) { \
struct nodeType * res = list->head; \
list->head = list->head->next##nodeType; \
list->head->prev##nodeType = NULL; \
list->size -= 1; \
return res; \
} \
\
uint32_t size_##nodeType##_list(nodeType##_list_t * list) { \
return list->size; \
} \
\
struct nodeType * next_##nodeType##_list(struct nodeType * node) { \
return node->next##nodeType; \
} \
#endif10-6-2. Utilisation▲
Si vous voulez une liste chaînée d'un certain type, dans le type, vous devez écrire DEFINE_LINK (typename). Ensuite, après que le type est défini, vous devez mettre DEFINE_LIST (typename); IMPLEMENT_LIST (typename). Cela générera un type de liste liée et des fonctions pour ce type.
Le type s'appellera typename_list_t. Ils doivent être créés en tant que variables globales et initialisés avant utilisation en utilisant INITIALIZE_LIST (instance)
Une fois cela fait, vous pouvez utiliser les fonctions. Elles sont toutes nommées action_typename_list, donc si vous voulez utiliser la liste comme une file d'attente, vous pouvez utiliser append_typename_list et pop_typename_list.
10-6-3. Un exemple▲
Supposons que vous ayez le type suivant et que vous souhaitiez le stocker dans une liste liée :
typedef struct point {
int x;
int y;
} point_t;Si vous deviez utiliser cette liste, vous mettriez ce qui suit dans le fichier d'en-tête :
typedef struct point {
int x;
int y;
DEFINE_LINK(point);
} point_t;
DEFINE_LIST(point);
IMPLEMENT_LIST(point);Ceci définit une liste chaînée qui ne peut contenir que des éléments de type structpoint, et implémente les fonctions de liste chaînée. La liste chaînée peut être utilisée comme ceci :
point_list_t points;
void do_something(point_t * point) {
INITIALIZE_LIST(points);
append_point_list(&points, point);
}10-7. Atags▲
Atags est une liste d'informations sur certains aspects du matériel. Cette liste est créée par le bootloader avant le chargement de notre noyau. Le bootloader la place à l'adresse 0x100, et transmet également cette adresse au noyau via le registre r2. Si vous regardez la signature de la fonction kernel_main, void kernel_main (uint32_t r0, uint32_t r1, uint32_t atags), vous pouvez voir que le pointeur atags est le troisième argument.
Les Atags peuvent nous dire quelle est la taille de la mémoire, où le bootloader a mis un ramdisk, quel est le numéro de série de la carte et la ligne de commande passée au noyau via cmdline.txt.
Un Atag se compose d'une taille (en mots de 4 octets), d'un identifiant de balise et d'informations spécifiques à la balise. La liste des Atags commence toujours par la balise CORE, ayant comme identifiant 0x54410001, et se termine par une balise NONE, ayant l'identifiant 0. Les balises sont concaténées de sorte que l'étiquette suivante de la liste peut être trouvée en ajoutant le nombre d'octets spécifié par la taille du pointeur Atag courant.
10-7-1. RĂ©fĂ©rence Atags▲
10-7-1-1. ATAG_CORE▲
ATAG_CORE : tag utilisé au début de la liste.
Valeur : 0x54410001.
Taille : 5 (2 si pas de données).
Membre structureÂ
struct atag_core {
u32 flags; /* bit 0 = lecture seule */
u32 pagesize; /* taille page système (habituellement 4k) */
u32 rootdev; /* numéro de device root */
};DescriptionÂ
Cette balise doit être utilisée pour démarrer la liste, elle contient les informations de base que tout bootloader doit transmettre, une longueur de balise de deux indique que la balise n'a pas de structure attachée.
10-7-1-2. ATAG_NONE▲
ATAG_NONE : tag vid utilisé en fin de liste.
Valeur : 0x00000000.
Taille : 2.
Membre structure
Aucun.
Description
Cette balise est utilisée pour indiquer la fin de la liste. Elle est particulière, car son champ de taille dans l'en-tête doit être mis à 0 (et pas 2).
10-7-1-3. ATAG_MEM▲
ATAG_MEM : balise utilisée pour décrire une zone mémoire physique.
Valeur : 0x54410002.
Taille : 4.
Champs de la structure :
struct atag_mem {
u32 size; /* taille de la zone */
u32 start; /* adresse physique de début */
};Description :
Décrit une zone de mémoire physique que le noyau peut utiliser.
10-7-1-4. ATAG_VIDEOTEXT▲
ATAG_VIDEOTEXT : balise utilisée pour décrire les affichages de type de texte VGA.
Valeur : 0x54410003.
Taille : 5.
Champs de la structure :
struct atag_videotext {
u8 x; /* largeur d'affichage */
u8 y; /* hauteur d'affichage */
u16 video_page;
u8 video_mode;
u8 video_cols;
u16 video_ega_bx;
u8 video_lines;
u8 video_isvga;
u16 video_points;
};10-7-1-5. ATAG_RAMDISK▲
ATAG_RAMDISK : balise décrivant comment le disque virtuel sera utilisé par le noyau.
Valeur : 0x54410004.
Taille : 5.
Champs de la structure :
struct atag_ramdisk {
u32 flags; /* bit 0 = chargement, bit 1 = prompt */
u32 size; /* taille ramdisk décompressé en _kilo_ octets */
u32 start; /* bloc de démarrage d'une image disque floppy-based */
};Description :
Décrit comment le ramdisk (initial) sera configuré par le noyau, en particulier cela permet au bootloader de s'assurer que le ramdisk sera suffisamment grand pour contenir l'image décompressée du disque mémoire initial que le bootloader passe via ATAG_INITRD2.
10-7-1-6. ATAG_INITRD2▲
ATAG_INITRD2 : balise décrivant l'emplacement physique de l'image ramdisk compressée.
Valeur : 0x54420005.
Taille : 4.
Champs de la structure :
struct atag_initrd2 {
u32 start; /* adresse physique de départ */
u32 size; /* taille en octets de l'image ramdisk compressée */
};Description :
Emplacement d'une image de disque virtuel compressée, généralement associée à un ATAG_RAMDISK. Peut être utilisé comme système de fichiers racine initial avec l'ajout d'un paramètre de ligne de commande « root=/dev/ram ». Cette balise remplace l'ATAG_INITRD d'origine qui utilisait l'adressage virtuel, c'était une erreur et cela causait des problèmes sur certains systèmes. Tous les nouveaux bootloaders devraient privilégier cette balise.
10-7-1-7. ATAG_SERIAL▲
ATAG_SERIAL : tag avec le numéro de série 64 bits de la carte.
Valeur : 0x54410006.
Taille : 4.
Champs de la structure :
struct atag_serialnr {
u32 low;
u32 high;
};10-7-1-8. ATAG_REVISION▲
ATAG_REVISION : tag pour la version de révision carte mère.
Valeur : 0x54410007.
Taille : 3.
Champs de la structure :
struct atag_revision {
u32 rev;
};10-7-1-9. ATAG_VIDEOLFB▲
ATAG_VIDEOLFB : balise décrivant les paramètres d'un affichage de type framebuffer.
Valeur : 0x54410008.
Taille : 8.
Champs de la structure :
struct atag_videolfb {
u16 lfb_width;
u16 lfb_height;
u16 lfb_depth;
u16 lfb_linelength;
u32 lfb_base;
u32 lfb_size;
u8 red_size;
u8 red_pos;
u8 green_size;
u8 green_pos;
u8 blue_size;
u8 blue_pos;
u8 rsvd_size;
u8 rsvd_pos;
};10-7-1-10. ATAG_CMDLINE▲
ATAG_CMDLINE : balise utilisée pour passer la ligne de commande au noyau.
Valeur : 0x54410009.
Taille : 2 + ((longueur_ligne_de_commande + 3) / 4).
Champs de la structure :
struct atag_cmdline {
char cmdline[1]; /* c'est la taille minimale */
};Description :
Utilisé pour passer les paramètres de la ligne de commande au noyau. La ligne de commande doit être terminée par NULL. La variable length_of_cmdline doit inclure la terminaison.
Exemple complet :
Voici un exemple simple de bootloader qui reprend toutes les informations expliquées tout au long de ce document. Plus de code serait requis pour implémenter un vrai bootloader. Cet exemple est purement illustratif.
Le code de cet exemple est distribué sous licence BSD, il peut être copié et utilisé gratuitement si nécessaire.
/* example.c
* exemple de code bootloader ARM Linux
* cet exemple est distribué sous licence BSD
*/
/* liste des tags possibles */
#define ATAG_NONE 0x00000000
#define ATAG_CORE 0x54410001
#define ATAG_MEM 0x54410002
#define ATAG_VIDEOTEXT 0x54410003
#define ATAG_RAMDISK 0x54410004
#define ATAG_INITRD2 0x54420005
#define ATAG_SERIAL 0x54410006
#define ATAG_REVISION 0x54410007
#define ATAG_VIDEOLFB 0x54410008
#define ATAG_CMDLINE 0x54410009
/* structures de chaque atag */
struct atag_header {
u32 size; /* longueur de la balise en mots incluant cet en-tĂŞte */
u32 tag; /* type de balise */
};
struct atag_core {
u32 flags;
u32 pagesize;
u32 rootdev;
};
struct atag_mem {
u32 size;
u32 start;
};
struct atag_videotext {
u8 x;
u8 y;
u16 video_page;
u8 video_mode;
u8 video_cols;
u16 video_ega_bx;
u8 video_lines;
u8 video_isvga;
u16 video_points;
};
struct atag_ramdisk {
u32 flags;
u32 size;
u32 start;
};
struct atag_initrd2 {
u32 start;
u32 size;
};
struct atag_serialnr {
u32 low;
u32 high;
};
struct atag_revision {
u32 rev;
};
struct atag_videolfb {
u16 lfb_width;
u16 lfb_height;
u16 lfb_depth;
u16 lfb_linelength;
u32 lfb_base;
u32 lfb_size;
u8 red_size;
u8 red_pos;
u8 green_size;
u8 green_pos;
u8 blue_size;
u8 blue_pos;
u8 rsvd_size;
u8 rsvd_pos;
};
struct atag_cmdline {
char cmdline[1];
};
struct atag {
struct atag_header hdr;
union {
struct atag_core core;
struct atag_mem mem;
struct atag_videotext videotext;
struct atag_ramdisk ramdisk;
struct atag_initrd2 initrd2;
struct atag_serialnr serialnr;
struct atag_revision revision;
struct atag_videolfb videolfb;
struct atag_cmdline cmdline;
} u;
};
#define tag_next(t) ((struct tag *)((u32 *)(t) + (t)->hdr.size))
#define tag_size(type) ((sizeof(struct tag_header) + sizeof(struct type)) >> 2)
static struct atag *params; /* utilisé pour pointer sur la balise courante */
static void
setup_core_tag(void * address,long pagesize)
{
params = (struct tag *)address; /* Initialise les paramètres pour démarrer à l'adresse donnée */
params->hdr.tag = ATAG_CORE; /* démarre avec la balise core */
params->hdr.size = tag_size(atag_core); /* taille de la balise */
params->u.core.flags = 1; /* garantit la lecture seule */
params->u.core.pagesize = pagesize; /* taille des pages système (4k) */
params->u.core.rootdev = 0; /* numéro de device racine (en général surchargé par la ligne de commande)*/
params = tag_next(params); /* place le pointeur sur la balise suivante */
}
static void
setup_ramdisk_tag(u32_t size)
{
params->hdr.tag = ATAG_RAMDISK; /* Balise ramdisk */
params->hdr.size = tag_size(atag_ramdisk); /* taille de la balise */
params->u.ramdisk.flags = 0; /* Charge le ramdisk */
params->u.ramdisk.size = size; /* taille du ramdisk décompressé */
params->u.ramdisk.start = 0; /* Inutilisé */
params = tag_next(params); /* place le pointeur sur la balise suivante */
}
static void
setup_initrd2_tag(u32_t start, u32_t size)
{
params->hdr.tag = ATAG_INITRD2; /* balise Initrd2 */
params->hdr.size = tag_size(atag_initrd2); /* taille de la balise */
params->u.initrd2.start = start; /* adresse physique début */
params->u.initrd2.size = size; /* taille ramdisk compressé */
params = tag_next(params); /* place le pointeur sur la balise suivante */
}
static void
setup_mem_tag(u32_t start, u32_t len)
{
params->hdr.tag = ATAG_MEM; /* balise mémoire */
params->hdr.size = tag_size(atag_mem); /* taille de la balise */
params->u.mem.start = start; /* Début de la zone mémoire (adresse physique) */
params->u.mem.size = len; /* longueur de la zone */
params = tag_next(params); /* place le pointeur sur la balise suivante */
}
static void
setup_cmdline_tag(const char * line)
{
int linelen = strlen(line);
if(!linelen)
return; /* ne pas insérer de balise pour une commandline vide */
params->hdr.tag = ATAG_CMDLINE; /* balise Commandline */
params->hdr.size = (sizeof(struct atag_header) + linelen + 1 + 4) >> 2;
strcpy(params->u.cmdline.cmdline,line); /* recopie la ligne de commande dans la balise */
params = tag_next(params); /* place le pointeur sur la balise suivante */
}
static void
setup_end_tag(void)
{
params->hdr.tag = ATAG_NONE; /* balise vide terminant la liste */
params->hdr.size = 0; /* longueur zero */
}
#define DRAM_BASE 0x10000000
#define ZIMAGE_LOAD_ADDRESS DRAM_BASE + 0x8000
#define INITRD_LOAD_ADDRESS DRAM_BASE + 0x800000
static void
setup_tags(parameters)
{
setup_core_tag(parameters, 4096); /* balise taille de page standard de 4k */
setup_mem_tag(DRAM_BASE, 0x4000000); /* 64Mo Ă 0x10000000 */
setup_mem_tag(DRAM_BASE + 0x8000000, 0x4000000); /* 64Mo Ă 0x18000000 */
setup_ramdisk_tag(4096); /* Crée un ramdisk de 4Mo */
setup_initrd2_tag(INITRD_LOAD_ADDRESS, 0x100000); /* 1Mo de données compressées placé dans 8Mo de mémoire */
setup_cmdline_tag("root=/dev/ram0"); /* ligne de commande définissant le device racine */
setup_end_tag(void); /* fin des tags */
}
int
start_linux(char *name,char *rdname)
{
void (*theKernel)(int zero, int arch, u32 params);
u32 exec_at = (u32)-1;
u32 parm_at = (u32)-1;
u32 machine_type;
exec_at = ZIMAGE_LOAD_ADDRESS;
parm_at = DRAM_BASE + 0x100
load_image(name, exec_at); /* copie l'image en RAM */
load_image(rdname, INITRD_LOAD_ADDRESS);/* copie l'image du ramdisk initial en RAM */
setup_tags(parm_at); /* configure les paramètres */
machine_type = get_mach_type(); /* récupère le type de machine */
irq_shutdown(); /* stoppe les irq */
cpu_op(CPUOP_MMUCHANGE, NULL); /* désactive la MMU */
theKernel = (void (*)(int, int, u32))exec_at; /* fixe l'adresse du noyau */
theKernel(0, machine_type, parm_at); /* appelle le noyau en ayant les registres paramétrés */
return 0;
}10-8. Framebuffer, pas, et profondeur▲
un Framebuffer est une partie de mémoire qui est partagée entre le CPU et le GPU. La CPU écrit des pixels RVB dans le tampon et le GPU le restitue sur n'importe quel périphérique de sortie connecté.
La profondeur d'un framebuffer est le nombre de bits utilisés pour chaque pixel. Pour ce tutoriel, nous utiliserons exclusivement une profondeur de 24 bits, ce qui signifie que chacune des valeurs rouges, vertes et bleues sera codée sur 8 bits, soit 1 octet.
Le pas d'un framebuffer est simplement le nombre d'octets pour chaque ligne Ă l'Ă©cran.
Nous pouvons calculer les Pixels par ligne par pitch/(profondeur/8), ou de manière équivalente (pitch * 8) / profondeur.
Nous pouvons calculer le décalage d'un pixel dans le framebuffer situé aux coordonnées (x, y) par pitch * y + (profondeur / 8) * x
10-9. Le pĂ©riphĂ©rique Mailbox▲
10-9-1. Aperçu de la Mailbox▲
Le périphérique Mailbox est un périphériqueSpécification périphérique et lecture écriture de base qui facilite la communication entre le processeur ARM et le GPU VideoCore. Il commence à offset 0xB880 et possède trois registres pertinents. Le registre de lecture est au décalage 0x00 de la base de la mailbox et facilite la lecture des messages du GPU. Les quatre bits inférieurs du registre indiquent de quel canal provient le message et les 28 bits supérieurs sont des données. Le registre d'état est à l'offset 0x18 de la base de la mailbox. Le bit 30 de ce registre peut vous indiquer si le registre Read est vide et le bit 31 peut vous indiquer si le registre Write est plein. Le registre d'écriture est au décalage 0x20, et a une forme similaire au registre de lecture. Voici la disposition du périphérique Mailbox :
|
|

Un canal est un nombre qui indique au GPU ce que signifie l'information envoyée par la boîte aux lettres. Nous n'aurons besoin que du canal 1, le framebuffer_channel et du canal 8, le property channel.
10-9-2. Lecture Ă partir de la Mailbox▲
Pour effectuer une lecture à partir de la mailbox, nous devons suivre les étapes suivantes :
- Dans une boucle, lire le registre d'état pour nous assurer que le registre de lecture n'est pas vide ;
- Lire le contenu du registre de lecture ;
- Vérifier le canal du message lu. Si ce n'est pas ce qui est attendu, faire quelque chose de sensé avec (ou l'ignorer) ;
- Si le canal est correct, récupérer les données.
Voici le code de la lecture :
mail_message_t mailbox_read(int channel) {
mail_status_t stat;
mail_message_t res;
// On s'assure que le message correspond au bon canal
do {
// On s'assure qu'il y a du courrier Ă recevoir
do {
stat = *MAIL0_STATUS;
} while (stat.empty);
// Récupération du message
res = *MAIL0_READ;
} while (res.channel != channel);
return res;
}Où mail_message_t et mail_status_t sont définis comme suit :
typedef struct {
uint8_t channel: 4;
uint32_t data: 28;
} mail_message_t;
typedef struct {
uint32_t reserved: 30;
uint8_t empty: 1;
uint8_t full:1;
} mail_status_t;10-9-2-1. Écrire dans la Mailbox▲
L'écriture suit un processus similaire à la lecture :
- Dans une boucle, vérifier le registre d'état pour voir si le registre d'écriture n'est pas plein ;
- Écrire les données dans le registre d'écriture.
Voici le code :
void mailbox_send(mail_message_t msg, int channel) {
mail_status_t stat;
msg.channel = channel;
// On s'assure que l'on peut envoyer le message
do {
stat = *MAIL0_STATUS;
} while (stat.full);
// envoi du message
*MAIL0_WRITE = msg;
}10-10. Le Framebuffer Mailbox Channel▲
10-10-1. Aperçu du Framebuffer Channel ▲
Le Framebuffer Channel est le canal 1 de la mailboxLe périphérique Mailbox, et c'est la « vieille » façon de demander au GPU un framebuffer. Cette méthode est utilisée pour le Raspberry Pi Modèle 1 uniquement. Pour le modèle 2 et supérieur, vous pouvez obtenir un framebuffer via le proprety channel.
10-10-2. Le Framebuffer Initialization Message▲
Le seul message que vous pouvez envoyer sur ce canal est un pointeur vers une structure d'initialisation, et le seul message que vous recevez est un message de réussite/échec. La structure d'initialisation ressemble à ceci :
typedef struct {
uint32_t width;
uint32_t height;
uint32_t vwidth;
uint32_t vheight;
uint32_t pitch;
uint32_t depth;
uint32_t ignorex;
uint32_t ignorey;
void * pointer;;
uint32_t size;
} fb_init_t;Dans cette structure, vous initialisez la largeur, la hauteur, la largeur virtuelle, la hauteur virtuelle et la profondeur de couleur souhaitées. La largeur et la hauteur sont mesurées en pixels, et pour ce tutoriel, nous utiliserons toujours 640x480. La largeur virtuelle et la hauteur virtuelle doivent simplement correspondre à la largeur et la hauteur. La profondeurFramebuffer, pas, et profondeur devrait être de 24.
Les valeurs de hauteur, de pointeur et de taille seront renseignées par le GPU. Le pointeur sera le framebuffer.
10-10-3. Envoi du message d'initialisation▲
Pour préparer ce message à être envoyé sur la boîte aux lettres, trois choses doivent être faites :
- S'assurer que la structure d'initialisation est alignée sur 16 octets, afin que l'adresse ne prenne que les 28 bits les plus élevés ;
- Ajouter 0x40000000 à l'adresse de la structure d'initialisation ;
- Au niveau du bit ou cette valeur avec 1, de sorte que le canal 1 prenne les 4 bits de poids faible.
Une fois ces opérations terminées, cette valeur peut être envoyée au GPU via la mailbox. Le GPU renvoie la même adresse via la mailbox en cas de succès, et 0 en cas d'erreur.
Vous avez peut-être remarqué que l'étape 2 est un peu étrange. Pourquoi ajoutons-nous 0x40000000 à notre adresse ? Parce que le GPU a la RAM mappée pour commencer à l'adresse physique 0x40000000 (si le cache de niveau 2 est activé, ce qui est le cas par défaut ; s'il est désactivé, l'adresse commence réellement à 0xC0000000). Lorsque le GPU accède à 0x40000000 + notre_adresse dans la mémoire physique, il accède en fait à notre adresse en mémoire vive. Le GPU utilise les adresses physiques situées en dessous de 0x40000000 pour les périphériques matériels avec MMIOSpécification périphérique et lecture écriture de base.
10-11. Le property mailbox channel▲
10-11-1. Aperçu du Property Channel▲
Le Property Channel est le canal 8 de la mailboxLe périphérique Mailbox et constitue la « nouvelle » façon de demander au GPU un framebuffer. Cette méthode est utilisée pour le Raspberry Pi Modèle 2 et plus. Pour le modèle 1, vous pouvez obtenir un framebuffer via le framebuffer channelLe Framebuffer Mailbox Channel.
Le property channel est un moyen d'obtenir et de définir des données sur divers périphériques matériels, dont le framebuffer fait partie.
10-11-2. Les messages Property Channel▲
Les messages ont une structure assez complexe et mal documentée. Un message doit être un tampon de 4 octets aligné sur 16 octets. La réponse écrase le message original.
Un message commence avec la taille du message sur 4 octets, y compris les 4 octets de la taille elle-mĂŞme.
La taille est suivie d'un code de requête/réponse de 4 octets. Lors de l'envoi d'un message, cette valeur doit être 0. Lors de la réception d'un message, cette partie sera soit 0x80000000 pour un succès soit 0x80000001 pour une erreur.
Après le code de demande/réponse vient une liste concaténée de balises. Les balises sont simultanément des commandes et des tampons pour les réponses à ces commandes. Il y a beaucoup de balises, mais nous ne parlerons que de celles qui nous concernent directement.
La toute dernière balise doit être une balise de fin, qui est juste 4 octets de 0.
Enfin, le message doit être complété de sorte que la taille du tampon entier soit alignée sur 16 octets.
Voici une carte du tampon de message :
|
|
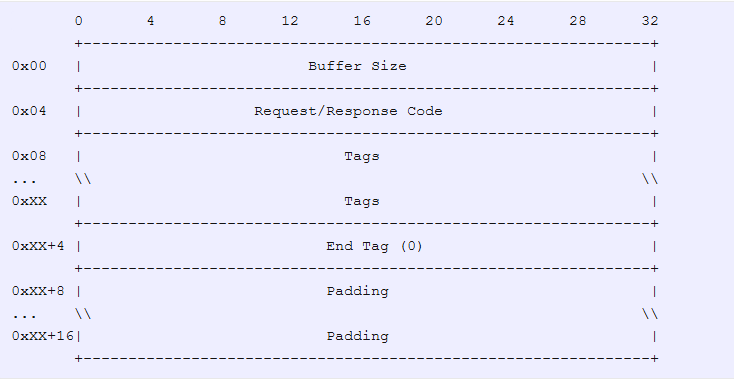
10-11-3. Balises Message ▲
Une balise est une commande spécifique utilisée pour obtenir ou définir certaines données sur le matériel.
Une balise commence par un identifiant de balise de 4 octets, qui identifie la commande que cette balise veut exécuter. En général, les balises ont le format 0x000XYZZZ, où X identifie le périphérique auquel vous accédez, Y identifie le type de commande (0 = get, 4 = test, 8 = set) et ZZZ identifie la commande spécifique.
Ensuite, la balise stocke la taille de son tampon de valeur en octets. La taille du tampon doit correspondre au maximum de la taille des paramètres de la commande et de la taille des résultats.
Ensuite, l'étiquette a son propre code de demande/réponse. Lors de l'envoi d'un message, la valeur doit être 0. Lors de la réception d'un message, la valeur doit être 0x80000000 + longueur du résultat.
Vient ensuite le tampon de valeurs, où les paramètres et les résultats sont stockés. Bien que le tampon de message contenant le tampon de valeur soit un tableau u32, le tampon de valeur est un tableau u8.
Enfin, nous avons besoin de remplissage pour aligner la balise sur 4 octets.
Voici une carte de la balise :
|
|
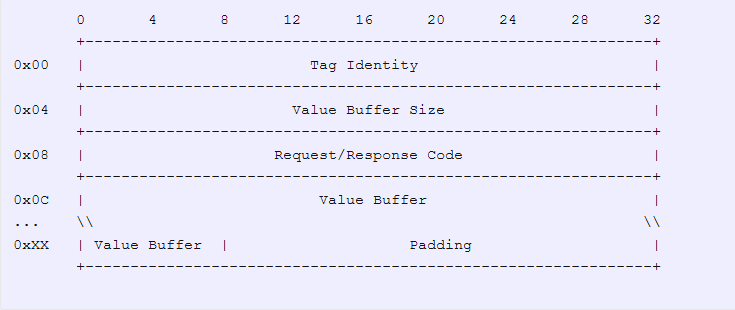
10-11-4. Obtenir un Framebuffer▲
La première étape pour obtenir un framebuffer consiste à définir la taille de l'écran, la taille de l'écran virtuel et la profondeur. Les identifiants des balises pour ces commandes sont respectivement 0x00048003, 0x00048004 et 0x00048005.
Pour définir la taille de l'écran, vous devez passer une largeur et une hauteur sur 4 octets, et il n'y a aucun retour. Par conséquent, le tampon de valeur a une taille de 8 octets pour les commandes de taille d'écran.
Pour définir la profondeur, vous devez passer une valeur de profondeur sur 4 octets, et il n'y a pas de retour. Par conséquent, le tampon de valeur a une taille de 4 octets.
Nous allons définir la taille de l'écran à 640x480 et la profondeur à 24.
Si nous les mettons ensemble dans un message, cela devrait ressembler à ceci :
80, // Le buffer fait 80 octets
0, // C'est une requête, donc le code requête/réponse est 0
0x00048003, 8, 0, 640, 480, // Ce tag fixe la taille d'Ă©cran Ă 640x480
0x00048004, 8, 0, 640, 480, // Ce tag fixe l'Ă©cran virtuel Ă 640x480
0x00048005, 4, 0, 24, // Ce tag fixe la profondeur Ă 24 bits
0, // C'est la balise de fin
0, 0, 0 // Ceci remplit le message pour être aligné sur 16 octetsNous devons ensuite envoyer ce tampon via la mailbox. Pour ce faire, nous devons nous assurer que notre tampon est situé à une adresse alignée sur 16 octets, donc seuls les 28 bits de poids fort contiennent l'adresse. Ensuite, nous devons régler les 4 bits de poids faible sur le numéro de canal. Enfin, nous pouvons l'envoyer via la mailbox en utilisant le processus décrit iciLe périphérique Mailbox. Afin de vérifier que cela a fonctionné, nous devons vérifier le code de demande/réponse de notre tampon. Si c'est 0, alors le message n'est pas passé correctement, car le GPU n'a pas pu écraser cette partie avec un code de réponse. Si c'est 0x80000001, une erreur est survenue. Si c'est 0x80000000, alors c'était réussi.
Maintenant que nous avons configuré les paramètres de l'écran, nous pouvons demander un framebuffer. L'ID de tag pour cette commande est 0x00040001. Cette commande prend un paramètre de 4 octets, l'alignement demandé du framebuffer, et renvoie deux valeurs de 4 octets, un pointeur vers le buffer et la taille de la mémoire tampon. Par conséquent, le tampon de valeur a la taille 8. Nous demanderons un tampon aligné de 16 octets.
Le message devrait ressembler à ceci :
32, // Le buffer fait 32 octets
0, // C'est une requête, donc le code de requête/réponse est 0
0x00040001, 8, 0, 16, 0, // Requête d'un framebuffer aligné sur 16 octets.
0 // C'est la balise de fin10-12. Bitmap police de caractères▲
#include <stdint.h>
#ifndef CHAR_BMPS_H
#define CHAR_BMPS_H
/* From https://github.com/dhepper/font8x8/blob/master/font8x8_block.h */
const uint8_t * font(int c) {
static const char f[128][8] = {
{ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00}, // U+0000 (nul)
{ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00}, // U+0001
{ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00}, // U+0002
{ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00}, // U+0003
{ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00}, // U+0004
{ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00}, // U+0005
{ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00}, // U+0006
{ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00}, // U+0007
{ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00}, // U+0008
{ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00}, // U+0009
{ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00}, // U+000A
{ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00}, // U+000B
{ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00}, // U+000C
{ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00}, // U+000D
{ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00}, // U+000E
{ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00}, // U+000F
{ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00}, // U+0010
{ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00}, // U+0011
{ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00}, // U+0012
{ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00}, // U+0013
{ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00}, // U+0014
{ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00}, // U+0015
{ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00}, // U+0016
{ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00}, // U+0017
{ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00}, // U+0018
{ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00}, // U+0019
{ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00}, // U+001A
{ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00}, // U+001B
{ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00}, // U+001C
{ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00}, // U+001D
{ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00}, // U+001E
{ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00}, // U+001F
{ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00}, // U+0020 (space)
{ 0x18, 0x3C, 0x3C, 0x18, 0x18, 0x00, 0x18, 0x00}, // U+0021 (!)
{ 0x36, 0x36, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00}, // U+0022 (")
{ 0x36, 0x36, 0x7F, 0x36, 0x7F, 0x36, 0x36, 0x00}, // U+0023 (#)
{ 0x0C, 0x3E, 0x03, 0x1E, 0x30, 0x1F, 0x0C, 0x00}, // U+0024 ($)
{ 0x00, 0x63, 0x33, 0x18, 0x0C, 0x66, 0x63, 0x00}, // U+0025 (%)
{ 0x1C, 0x36, 0x1C, 0x6E, 0x3B, 0x33, 0x6E, 0x00}, // U+0026 (&)
{ 0x06, 0x06, 0x03, 0x00, 0x00, 0x00, 0x00, 0x00}, // U+0027 (')
{ 0x18, 0x0C, 0x06, 0x06, 0x06, 0x0C, 0x18, 0x00}, // U+0028 (()
{ 0x06, 0x0C, 0x18, 0x18, 0x18, 0x0C, 0x06, 0x00}, // U+0029 ())
{ 0x00, 0x66, 0x3C, 0xFF, 0x3C, 0x66, 0x00, 0x00}, // U+002A (*)
{ 0x00, 0x0C, 0x0C, 0x3F, 0x0C, 0x0C, 0x00, 0x00}, // U+002B (+)
{ 0x00, 0x00, 0x00, 0x00, 0x00, 0x0C, 0x0C, 0x06}, // U+002C (,)
{ 0x00, 0x00, 0x00, 0x3F, 0x00, 0x00, 0x00, 0x00}, // U+002D (-)
{ 0x00, 0x00, 0x00, 0x00, 0x00, 0x0C, 0x0C, 0x00}, // U+002E (.)
{ 0x60, 0x30, 0x18, 0x0C, 0x06, 0x03, 0x01, 0x00}, // U+002F (/)
{ 0x3E, 0x63, 0x73, 0x7B, 0x6F, 0x67, 0x3E, 0x00}, // U+0030 (0)
{ 0x0C, 0x0E, 0x0C, 0x0C, 0x0C, 0x0C, 0x3F, 0x00}, // U+0031 (1)
{ 0x1E, 0x33, 0x30, 0x1C, 0x06, 0x33, 0x3F, 0x00}, // U+0032 (2)
{ 0x1E, 0x33, 0x30, 0x1C, 0x30, 0x33, 0x1E, 0x00}, // U+0033 (3)
{ 0x38, 0x3C, 0x36, 0x33, 0x7F, 0x30, 0x78, 0x00}, // U+0034 (4)
{ 0x3F, 0x03, 0x1F, 0x30, 0x30, 0x33, 0x1E, 0x00}, // U+0035 (5)
{ 0x1C, 0x06, 0x03, 0x1F, 0x33, 0x33, 0x1E, 0x00}, // U+0036 (6)
{ 0x3F, 0x33, 0x30, 0x18, 0x0C, 0x0C, 0x0C, 0x00}, // U+0037 (7)
{ 0x1E, 0x33, 0x33, 0x1E, 0x33, 0x33, 0x1E, 0x00}, // U+0038 (8)
{ 0x1E, 0x33, 0x33, 0x3E, 0x30, 0x18, 0x0E, 0x00}, // U+0039 (9)
{ 0x00, 0x0C, 0x0C, 0x00, 0x00, 0x0C, 0x0C, 0x00}, // U+003A (:)
{ 0x00, 0x0C, 0x0C, 0x00, 0x00, 0x0C, 0x0C, 0x06}, // U+003B (//)
{ 0x18, 0x0C, 0x06, 0x03, 0x06, 0x0C, 0x18, 0x00}, // U+003C (<)
{ 0x00, 0x00, 0x3F, 0x00, 0x00, 0x3F, 0x00, 0x00}, // U+003D (=)
{ 0x06, 0x0C, 0x18, 0x30, 0x18, 0x0C, 0x06, 0x00}, // U+003E (>)
{ 0x1E, 0x33, 0x30, 0x18, 0x0C, 0x00, 0x0C, 0x00}, // U+003F (?)
{ 0x3E, 0x63, 0x7B, 0x7B, 0x7B, 0x03, 0x1E, 0x00}, // U+0040 (@)
{ 0x0C, 0x1E, 0x33, 0x33, 0x3F, 0x33, 0x33, 0x00}, // U+0041 (A)
{ 0x3F, 0x66, 0x66, 0x3E, 0x66, 0x66, 0x3F, 0x00}, // U+0042 (B)
{ 0x3C, 0x66, 0x03, 0x03, 0x03, 0x66, 0x3C, 0x00}, // U+0043 (C)
{ 0x1F, 0x36, 0x66, 0x66, 0x66, 0x36, 0x1F, 0x00}, // U+0044 (D)
{ 0x7F, 0x46, 0x16, 0x1E, 0x16, 0x46, 0x7F, 0x00}, // U+0045 (E)
{ 0x7F, 0x46, 0x16, 0x1E, 0x16, 0x06, 0x0F, 0x00}, // U+0046 (F)
{ 0x3C, 0x66, 0x03, 0x03, 0x73, 0x66, 0x7C, 0x00}, // U+0047 (G)
{ 0x33, 0x33, 0x33, 0x3F, 0x33, 0x33, 0x33, 0x00}, // U+0048 (H)
{ 0x1E, 0x0C, 0x0C, 0x0C, 0x0C, 0x0C, 0x1E, 0x00}, // U+0049 (I)
{ 0x78, 0x30, 0x30, 0x30, 0x33, 0x33, 0x1E, 0x00}, // U+004A (J)
{ 0x67, 0x66, 0x36, 0x1E, 0x36, 0x66, 0x67, 0x00}, // U+004B (K)
{ 0x0F, 0x06, 0x06, 0x06, 0x46, 0x66, 0x7F, 0x00}, // U+004C (L)
{ 0x63, 0x77, 0x7F, 0x7F, 0x6B, 0x63, 0x63, 0x00}, // U+004D (M)
{ 0x63, 0x67, 0x6F, 0x7B, 0x73, 0x63, 0x63, 0x00}, // U+004E (N)
{ 0x1C, 0x36, 0x63, 0x63, 0x63, 0x36, 0x1C, 0x00}, // U+004F (O)
{ 0x3F, 0x66, 0x66, 0x3E, 0x06, 0x06, 0x0F, 0x00}, // U+0050 (P)
{ 0x1E, 0x33, 0x33, 0x33, 0x3B, 0x1E, 0x38, 0x00}, // U+0051 (Q)
{ 0x3F, 0x66, 0x66, 0x3E, 0x36, 0x66, 0x67, 0x00}, // U+0052 (R)
{ 0x1E, 0x33, 0x07, 0x0E, 0x38, 0x33, 0x1E, 0x00}, // U+0053 (S)
{ 0x3F, 0x2D, 0x0C, 0x0C, 0x0C, 0x0C, 0x1E, 0x00}, // U+0054 (T)
{ 0x33, 0x33, 0x33, 0x33, 0x33, 0x33, 0x3F, 0x00}, // U+0055 (U)
{ 0x33, 0x33, 0x33, 0x33, 0x33, 0x1E, 0x0C, 0x00}, // U+0056 (V)
{ 0x63, 0x63, 0x63, 0x6B, 0x7F, 0x77, 0x63, 0x00}, // U+0057 (W)
{ 0x63, 0x63, 0x36, 0x1C, 0x1C, 0x36, 0x63, 0x00}, // U+0058 (X)
{ 0x33, 0x33, 0x33, 0x1E, 0x0C, 0x0C, 0x1E, 0x00}, // U+0059 (Y)
{ 0x7F, 0x63, 0x31, 0x18, 0x4C, 0x66, 0x7F, 0x00}, // U+005A (Z)
{ 0x1E, 0x06, 0x06, 0x06, 0x06, 0x06, 0x1E, 0x00}, // U+005B ([)
{ 0x03, 0x06, 0x0C, 0x18, 0x30, 0x60, 0x40, 0x00}, // U+005C (\)
{ 0x1E, 0x18, 0x18, 0x18, 0x18, 0x18, 0x1E, 0x00}, // U+005D (])
{ 0x08, 0x1C, 0x36, 0x63, 0x00, 0x00, 0x00, 0x00}, // U+005E (^)
{ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0xFF}, // U+005F (_)
{ 0x0C, 0x0C, 0x18, 0x00, 0x00, 0x00, 0x00, 0x00}, // U+0060 (`)
{ 0x00, 0x00, 0x1E, 0x30, 0x3E, 0x33, 0x6E, 0x00}, // U+0061 (a)
{ 0x07, 0x06, 0x06, 0x3E, 0x66, 0x66, 0x3B, 0x00}, // U+0062 (b)
{ 0x00, 0x00, 0x1E, 0x33, 0x03, 0x33, 0x1E, 0x00}, // U+0063 (c)
{ 0x38, 0x30, 0x30, 0x3e, 0x33, 0x33, 0x6E, 0x00}, // U+0064 (d)
{ 0x00, 0x00, 0x1E, 0x33, 0x3f, 0x03, 0x1E, 0x00}, // U+0065 (e)
{ 0x1C, 0x36, 0x06, 0x0f, 0x06, 0x06, 0x0F, 0x00}, // U+0066 (f)
{ 0x00, 0x00, 0x6E, 0x33, 0x33, 0x3E, 0x30, 0x1F}, // U+0067 (g)
{ 0x07, 0x06, 0x36, 0x6E, 0x66, 0x66, 0x67, 0x00}, // U+0068 (h)
{ 0x0C, 0x00, 0x0E, 0x0C, 0x0C, 0x0C, 0x1E, 0x00}, // U+0069 (i)
{ 0x30, 0x00, 0x30, 0x30, 0x30, 0x33, 0x33, 0x1E}, // U+006A (j)
{ 0x07, 0x06, 0x66, 0x36, 0x1E, 0x36, 0x67, 0x00}, // U+006B (k)
{ 0x0E, 0x0C, 0x0C, 0x0C, 0x0C, 0x0C, 0x1E, 0x00}, // U+006C (l)
{ 0x00, 0x00, 0x33, 0x7F, 0x7F, 0x6B, 0x63, 0x00}, // U+006D (m)
{ 0x00, 0x00, 0x1F, 0x33, 0x33, 0x33, 0x33, 0x00}, // U+006E (n)
{ 0x00, 0x00, 0x1E, 0x33, 0x33, 0x33, 0x1E, 0x00}, // U+006F (o)
{ 0x00, 0x00, 0x3B, 0x66, 0x66, 0x3E, 0x06, 0x0F}, // U+0070 (p)
{ 0x00, 0x00, 0x6E, 0x33, 0x33, 0x3E, 0x30, 0x78}, // U+0071 (q)
{ 0x00, 0x00, 0x3B, 0x6E, 0x66, 0x06, 0x0F, 0x00}, // U+0072 (r)
{ 0x00, 0x00, 0x3E, 0x03, 0x1E, 0x30, 0x1F, 0x00}, // U+0073 (s)
{ 0x08, 0x0C, 0x3E, 0x0C, 0x0C, 0x2C, 0x18, 0x00}, // U+0074 (t)
{ 0x00, 0x00, 0x33, 0x33, 0x33, 0x33, 0x6E, 0x00}, // U+0075 (u)
{ 0x00, 0x00, 0x33, 0x33, 0x33, 0x1E, 0x0C, 0x00}, // U+0076 (v)
{ 0x00, 0x00, 0x63, 0x6B, 0x7F, 0x7F, 0x36, 0x00}, // U+0077 (w)
{ 0x00, 0x00, 0x63, 0x36, 0x1C, 0x36, 0x63, 0x00}, // U+0078 (x)
{ 0x00, 0x00, 0x33, 0x33, 0x33, 0x3E, 0x30, 0x1F}, // U+0079 (y)
{ 0x00, 0x00, 0x3F, 0x19, 0x0C, 0x26, 0x3F, 0x00}, // U+007A (z)
{ 0x38, 0x0C, 0x0C, 0x07, 0x0C, 0x0C, 0x38, 0x00}, // U+007B ({)
{ 0x18, 0x18, 0x18, 0x00, 0x18, 0x18, 0x18, 0x00}, // U+007C (|)
{ 0x07, 0x0C, 0x0C, 0x38, 0x0C, 0x0C, 0x07, 0x00}, // U+007D (})
{ 0x6E, 0x3B, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00}, // U+007E (~)
{ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00} // U+007F
};
return (uint8_t *)f[c];
}
#endif10-13. Charger le noyau dans du vrai matĂ©riel▲
Pour charger le noyau sur du matériel réel, vous devez effectuer les opérations suivantes :
- Assurez-vous que vous avez une carte SD qui peut démarrer un système d'exploitation complet comme Raspbian ;
- Extrayez le code du fichier elf pour former un fichier binaire brut. Vous pouvez le faire en ajoutant OBJCOPY = ./gcc-arm-none-eabi-X-XXXX-XX-update/bin/arm-none-eabi-objcopy en haut du fichier makefile, et en ajoutant $ (OBJCOPY) $ ( IMG_NAME) .elf -O binaire $ (IMG_NAME) .img à la cible de génération ;
- Montez votre carte SD sur l'ordinateur où vous développez ;
- Il devrait y avoir un fichier appelé kernel.img si vous avez un Modèle 1, et kernel7.img pour un Modèle 2 ou 3. Renommez celui-ci autrement ;
- Copiez le noyau binaire brut sur la carte SD et nommez-le kernel.img sur le modèle 1 et kernel7.img sur les modèles 2 et 3 ;
- Éjectez la carte SD en toute sécurité et démarrez le Raspberry Pi.
10-14. Interruptions et exceptions▲
10-14-1. Exceptions▲
Une exception est un événement qui se déclenche lorsqu'un événement exceptionnel se produit pendant l'exécution normale du programme. Des exemples de telles occurrences exceptionnelles comprennent des dispositifs matériels présentant de nouvelles données au CPU, un code utilisateur essayant d'effectuer une action demandant des privilèges, et une mauvaise instruction qui a été rencontrée.
Sur le Raspberry Pi, lorsqu'une exception se produit, une adresse spécifique est chargée dans le registre du compteur de programme, branchant l'exécution à ce point. À cet emplacement, le développeur du noyau doit écrire des instructions de branchement aux routines qui gèrent les exceptions. Cet ensemble d'adresses, également connu sous le nom de Tableau de vecteurs, commence à l'adresse 0. Voici un tableau qui décrit chaque exception :
|
Adresse |
Nom de l'exception |
Source de l'exception |
Action requise |
|---|---|---|---|
|
0x00 |
Reset |
Réinitialisation matérielle |
Redémarrer le noyau |
|
0x04 |
instruction indéfinie |
Tentative d'exécution d'une instruction sans signification |
Tuer le programme incriminé |
|
0x08 |
Software Interrupt (SWI) |
Un logiciel veut exécuter une opération privilégiée |
Effectuer l'opération et retourner à l'appelant |
|
0x0C |
Prefetch Abort |
Mauvais accès mémoire d'une instruction |
Tuer le programme incriminé |
|
0x10 |
Data Abort |
Mauvais accès à une donnée |
Tuer le programme incriminé |
|
0x14 |
Reservé |
Réservé |
Réservé |
|
0x18 |
Interrupt Request (IRQ) |
Le matériel veut faire prendre conscience au CPU de quelque chose |
Trouver quel équipement a déclenché l'interruption et prendre les mesures appropriées |
|
0x1C |
Fast Interrupt Request (FIQ) |
Un matériel sélectionné peut faire l'action ci-dessus plus vite que les autres |
Trouver quel équipement a déclenché l'interruption et prendre les mesures appropriées |
10-14-2. RequĂŞtes d'interruption (Interrupt Requests)▲
Une demande d'interruption ou IRQ est une notification au processeur que quelque chose est arrivé à ce matériel que le processeur devrait connaître. Cela peut se manifester sous différentes formes, comme la pression d'une touche, l'accès à de la mémoire privilégiée ou la réception d'un paquet réseau.
Pour déterminer quels périphériques matériels sont autorisés à déclencher des interruptions et déterminer quel périphérique a déclenché une interruption, nous devons utiliser le périphérique IRQ, qui démarre au décalage 0xB000 à partir de l'adresse de base du périphérique. Ce périphérique dispose de trois types de registres : en attente, activé et désactivé. Les registres en attente indiquent si une interruption donnée a été déclenchée. Ils sont utilisés afin de déterminer quel périphérique matériel a déclenché l'exception IRQ. Activer les registres permet de déclencher certaines interruptions en définissant le bit approprié ; désactiver les registres de désactiver certaines interruptions en définissant le bit approprié.
Le Raspberry Pi a 72 IRQ possibles. Les IRQ 0 à 63 sont partagées entre le GPU et le CPU, et les IRQ 64 à 71 sont spécifiques au CPU. Les deux IRQ les plus importantes pour nos besoins seront la minuterie du système (le timer :IRQ numéro 1) et le contrôleur USB (numéro IRQ 9).
Voici la disposition du périphérique IRQ :
|
|

Voici deux points qui méritent une explication à propos de ce périphérique :
- Lorsque vous voyez qu'une interruption est en attente, vous ne devez pas effacer ce bit. Chaque périphérique qui peut déclencher une interruption a son propre mécanisme pour effacer le bit en attente qui doit être fait dans le gestionnaire pour l'IRQ de ce périphérique ;
- Effacer un bit dans un registre d'activation n'est ni suffisant ni nécessaire pour désactiver une IRQ. Une IRQ ne doit être désactivée qu'en définissant le bit correct dans le registre de désactivation.
10-15. Une explication dĂ©taillĂ©e d'interrupt_vector.S▲
10-15-1. Source d'interrupt_vector.S▲
Rappel du code source de interrupt_vector.SÂ :
.section ".text"
.global move_exception_vector
exception_vector:
ldr pc, reset_handler_abs_addr
ldr pc, undefined_instruction_handler_abs_addr
ldr pc, software_interrupt_handler_abs_addr
ldr pc, prefetch_abort_handler_abs_addr
ldr pc, data_abort_handler_abs_addr
nop // ceci est réservé
ldr pc, irq_handler_abs_addr
ldr pc, fast_irq_handler_abs_addr
reset_handler_abs_addr: .word reset_handler
undefined_instruction_handler_abs_addr: .word undefined_instruction_handler
software_interrupt_handler_abs_addr: .word software_interrupt_handler
prefetch_abort_handler_abs_addr: .word prefetch_abort_handler
data_abort_handler_abs_addr: .word data_abort_handler
irq_handler_abs_addr: .word irq_handler_asm_wrapper
fast_irq_handler_abs_addr: .word fast_irq_handler
move_exception_vector:
push {r4, r5, r6, r7, r8, r9}
ldr r1, =exception_vector
mov r1, #0x0000
ldmia r0!,{r2, r3, r4, r5, r6, r7, r8, r9}
stmia r1!,{r2, r3, r4, r5, r6, r7, r8, r9}
ldmia r0!,{r2, r3, r4, r5, r6, r7, r8}
stmia r1!,{r2, r3, r4, r5, r6, r7, r8}
pop {r4, r5, r6, r7, r8, r9}
blx lr
irq_handler_asm_wrapper:
sub lr, lr, #4
srsdb sp!, #0x13
cpsid if, #0x13
push {r0-r3, r12, lr}
and r1, sp, #4
sub sp, sp, r1
push {r1}
bl irq_handler
pop {r1}
add sp, sp, r1
pop {r0-r3, r12, lr}
rfeia sp!10-15-2. Écrire la table des vecteurs d'exception▲
Notre stratégie consiste à écrire chaque instruction de branchement à la main et à copier les instructions de la section .text à l'adresse 0 lors de l'exécution.
La première chose à remarquer est que nos instructions de branchement ne sont pas :
ldr pc, irq_handlermais :
ldr pc, irq_handler_abs_addr
...
irq_handler_abs_addr: .word irq_handlerCeci est dû à l'option -fpic de gcc, qui signifie « code indépendant de la position ». Cela signifie que si nous devions écrire ldr pc, irq_handler, il serait compilé en ldr pc, [pc, #offset_to_irq_handler]. Ceci charge l'adresse par rapport à sa position courante. Cependant, lorsque nous déplaçons l'instruction vers l'adresse 0, le gestionnaire ne serait plus au même décalage relatif.
Pour résoudre ce problème, nous devons mettre l'adresse absolue du gestionnaire en mémoire proche, et charger cette adresse par rapport à la position courante. C'est ce que nous avons fait ci-dessus.
10-15-3. DĂ©placer la table de vecteurs d'exception▲
move_exception_vector est une fonction qui sera appelée à partir d'interrupts_init dans interrupt.c. Je vais parcourir celle-ci ligne par ligne.
push {r4, r5, r6, r7, r8, r9}Cette instruction sauvegarde les registres situés au-dessus de r3 que la fonction utilisera. Les fonctions d'appel C s'attendent à ce que ces registres soient sauvegardés pour eux, nous devons donc le faire et les restaurer plus tard.
ldr r0, =exception_vectorCharge l'adresse d' exception_vector dans r0.
mov r1, #0x0000r1 est l'adresse de destination.
ldmia r0!,{r2, r3, r4, r5, r6, r7, r8, r9}
stmia r1!,{r2, r3, r4, r5, r6, r7, r8, r9}ldm charge les données de r0 dans les registres r2-r9. Le suffixe ia signifie qu'après l'enregistrement dans chaque registre, il faut incrémenter l'adresse pour que le registre suivant obtienne le mot de mémoire suivant. Le ! signifie stocker l'adresse après le dernier mot de la mémoire copié dans r0 de sorte que nous pouvons recommencer à partir de cet endroit plus tard. Ceci charge les 8 mots d'exception de leur emplacement de départ dans des registres. L'instruction suivante fait la même chose, mais à l'inverse, écrit les valeurs du registre à l'adresse 0.
ldmia r0!,{r2, r3, r4, r5, r6, r7, r8}
stmia r1!,{r2, r3, r4, r5, r6, r7, r8}Cela répète ce qui précède, mais copie les adresses absolues au-dessus des instructions d'exception.
pop {r4, r5, r6, r7, r8, r9}
blx lrCeci restaure les registres sauvegardés et retourne à l'appelant.
10-15-4. Un wrapper de gestionnaire personnalisĂ©▲
Les exceptions ne peuvent pas simplement sauter vers les fonctions normales. Il y a certaines choses qui doivent être prises en compte avant et après l'exécution de la fonction normale. En utilisant __attribute __ ((interruption ("FIQ"))), nous pouvons intégrer une version spéciale par défaut de ce prologue et de cet épilogue directement dans la fonction. Cependant, il est très minime, et pour notre gestionnaire d'IRQ, nous avons besoin d'un peu de personnalisation.
Analysons le code :
sub lr, lr, #4En raison d'une bizarrerie de la gestion des exceptions des processeurs ARM, nous devons ajuster l'adresse de retour d'une instruction en arrière.
srsdb sp!, #0x13Lorsqu'une exception IRQ se produit, le processeur bascule de n'importe quel mode vers le mode IRQ. Le mode IRQ possède sa propre pile et ses propres versions de quelques registres, y compris sp et cpsr, qui sont distincts des registres normaux. Cela rendra la vie plus facile à long terme si nous passons du mode IRQ au mode superviseur, ce qui est notre point de départ.
Cette instruction stocke lr (l'adresse de retour) et spsr (le registre cpsr général qui est occulté par la propre version du mode IRQ) dans la pile du mode 0x13 (mode superviseur), puis utilise le pointeur de pile de ce mode.
cpsid if, #0x13Cette instruction passe en mode superviseur avec les interruptions désactivées.
push {r0-r3, r12, lr}Cela sauvegarde tous les registres de l'appelant qui doivent l'être. Toute fonction que nous appelons va sauvegarder les registres r4 à r11 pour nous et les restituer pour nous, donc on ne remarque pas la différence. Nous devons sauver r0 à r3, r12 et lr. Les fonctions « normales » acceptent généralement que ces registres soient écrasés et ne les sauvegardent pas. Puisque nous interrompons un autre code qui n'est pas préparé à l'appel d'une fonction, nous devons conserver tous les registres afin qu'il ne remarque pas que quelque chose s'est passé une fois le contrôle lui étant rendu.
and r1, sp, #4
sub sp, sp, r1Selon la documentation ARM, la pile doit être alignée sur 8 octets lors de l'appel des fonctions, pourtant le gestionnaire d'exceptions peut nous laisser une pile qui n'est pas alignée sur 8 octets. Ce code corrige cela.
bl irq_handlerCeci appelle notre gestionnaire en C.
add sp, sp, r1Ceci restaure l'alignement de la pile.
pop {r0-r3, r12, lr}Ceci restaure les registres de l'appelant.
rfeia sp!Ceci restaure la sauvegarde de cpsr et retourne à l'adresse stockée dans lr.
10-16. Le pĂ©riphĂ©rique système timer▲
Le timer système est une horloge matérielle qui peut être utilisée pour conserver l'heure et générer des interruptions après un certain temps. Il est situé au décalage 0x3000 de la base périphériqueLes entrées/sorties mappées en mémoire, les périphériques et les registres.
Le timer système est une minuterie autonome qui incrémente un compteur de 64 bits toutes les microsecondes, en commençant dès que le Pi démarre et fonctionne en arrière-plan aussi longtemps que le Pi est activé.
Il y a quatre registres de comparaison dont le compteur compare les 32 bits de poids faible à chaque tic. Si un registre de comparaison correspond au compteur, une IRQ est déclenchée. Chaque registre de comparaison dispose de sa propre interruption, les numéros d'interruption 0 à 3. Les registres de comparaison 0 et 2 sont utilisés par le GPU et ne devraient probablement pas être manipulés, mais les registres 1 et 3 sont disponibles pour notre utilisation.
Il y a aussi un registre de contrôle. Les quatre bits inférieurs sont des drapeaux qui indiquent si une interruption a été déclenchée ou non. L'effacement de ce bit efface l'indicateur d'interruption en attente pour ce timer.
Voici la disposition du périphérique de minuterie :
|
|

11. Notes de la rĂ©daction▲
La rédaction remercie Jake Sandler pour l'autorisation de traduction de son article :
« Building an Operating System for the Raspberry Pi ».
La rédaction remercie également :
Chrtophe pour sa traduction ;
Jlliagre et Winjerome pour leurs corrections ;
Claude Leloup pour sa relecture orthographique.